视频理解综述-从 I3D 到 video transformers
摘要
这篇文章将会从 I3D 接手记录近年来在视频理解领域的各个 SOTA。所有内容包括 3DCNN 和 transformer 两个大类,具体来说包含如下论文:
在 I3D 发布之后,I3D 迅速成为了视频理解的 SOTA,其提出的结构具备易训练、效果好等特点。在此之后 3DCNN 开始了大流行,基本完全代替了 2DCNN+RNN 的位置,但是仍然存在两个问题:1.使用 I3D 的网络必须以一个 2D 网络为 backbone,2.仍然依赖光流。因此接下来的一部分工作仍然致力于尝试从头训练 3D 网络以及试着剔除光流。
为了能够从头训练 3D 网络,受到 Non-local-mean 算子的启发,FAIR 在网络中引入了 non-local 算子,成功在不使用 3DConv 的情况下获得了比 I3D 更好的结果。当然,在 I3D 中加入 non-local 将会更好。同年,为了降低 3D 网络的参数,FAIR 提出了一种拆分 3D 卷积核的方法,即先做空间卷积再做时间卷积,也就是 R(2+1)D,这项工作显著降低了 3D 网络的训练难度,可以从头训练 3D 结构,但是效果仅和 I3D 持平。在这之后,FAIR 借鉴人眼细胞中观察静态和动态视频的细胞数目,摒弃光流,将视频帧按照不同的步长截取 clip,分别进入不同参数量的网络,得到了 SlowFast,同时加上 NL 操作,在 K400/600 上全面超过了 I3D。
此时时间已经到达了 2021 年,随着 VIT 的提出,将 VIT 向视频领域的迁移完全盖过了 3DCNN 的风头,theator 首先提出了 VTN,以一个 CNN 结构抽取特征,后接 transformer 结构进行时间注意力建模,以 VIT-B 为backbone 的结构在 K400 上超过了 SlowFast。同年,借助 R(2+1)D 的思路,FAIR 又提出了 Timesformer,分别对时空做自注意力,显著降低了 3D-SA 的复杂度,将 K400 的 top-1 分数刷到了 80+。同时 Google Research 提出了 ViViT,开发出了独立的时空注意力模块(其中的 SOTA 方法和 Timesformer 一样的,就别写了,JFT 效果好和我等屁民也无关),以小尺寸的输入和 IN-21K 的预训练超了 Timesformer,同时在 JFT 预训练上拉到了 83+,一骑绝尘。片刻之后,FAIR 又提出了以多尺度图像信息作为输入的 MViT,在 K400 上超了 Timesformer,拉平了在 IN-21K 上做预训练的 ViViT,毕竟 MViT 没有做预训练。时至今日,MSRA 在 swinTransformer 的基础上做出了 VideoSwinTransformer,在 IN-21K 上预训练,超过了 ViViT,在 K400 的 top-1 上得到了 84.9 的准确率。
FAIR 🐮🍺
概览
Non-local
Non-local Neural Networks 【视频动作识别】 CVPR2018
创新
- 提出了一种可以接入在 2D/3D 网络结构任意位置的模块 non-local block(NL)
- NL 可以计算全局的位置信息,但区别于 DNN,更接近 SA
网络结构
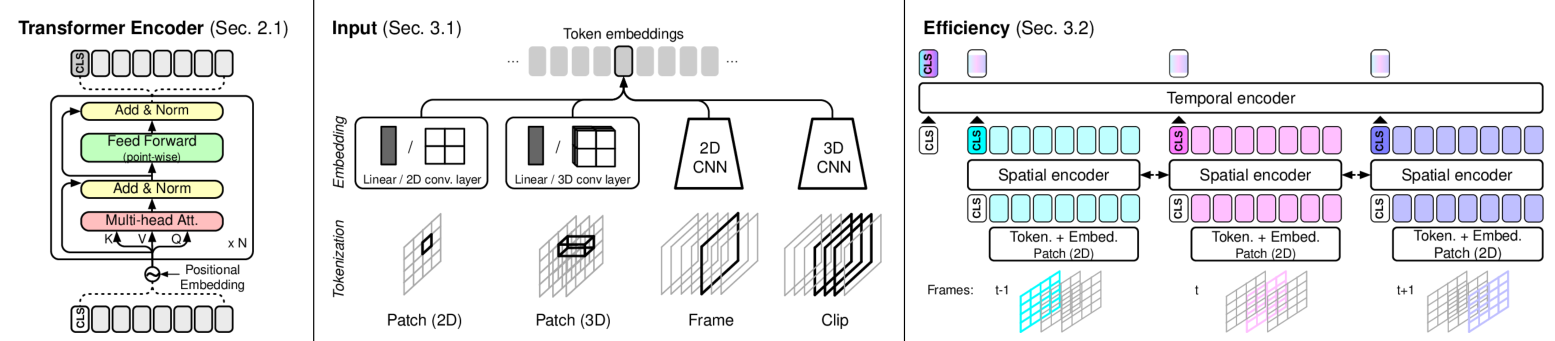
这项工作选取了 Res50 和 Res101 作为 backbone,分别在 C2D 和 I3D 上不同位置加入了 NL,区别于原本的双流 I3D,取消了光流的输入,以在 Res50 C2D 版本的 res2/3 中加入 5 个 NL 来说,大致网络结构如下:

如果除去蓝色小块,剩下的就是标准的 Res50,对于不同的 NL 个数:1/5/10,全部在 stage2/3 之中加入,或隔一个加一个,或全部后接 NL。这样做的原因是:1.NL 操作复杂度较高,直接在 stage1 后接,会导致训练变慢,2.在 stage4 后接的话,此时的特征图已经太小,并且这个时候的感受野已经很大了,再接入 NL 意义不大。具体到某一个 NL_block,其具体的计算方式如下:
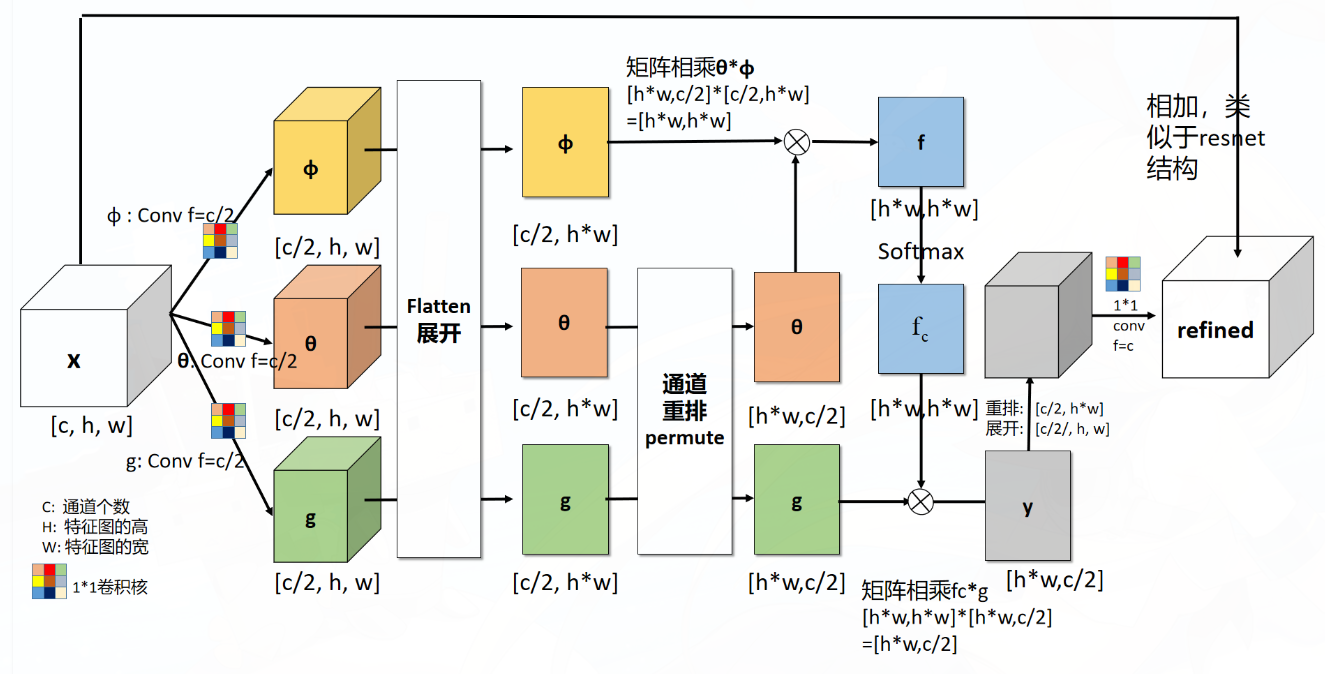
看上去是很复杂的,其实就是带残差连接的 SA。上面的这个实现可以直接复现出源码,在论文中,作者也给出了抽象的 NL_block 的实现方式:
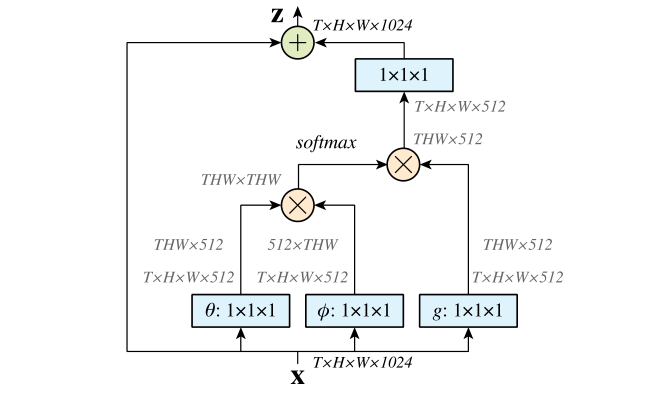
这个实现方式也十分直观,但在实现的源码中,这里的 embedding 之后并不一定是 512 维,而是可变的。除此之外,无论是 2D/3D 的卷积层得到的输出 (b,c,h,w)/(b,c,d,h,w) 都可以直接进入 NL_block,输出的维度和原本一致,由于输入的 x 自带 shape 信息,因此真的完全不需要任何其他的输入,你只需要指定你想要的 embedding_dim 就可以了。
除了如何在代码意义上实现 NL,作者自然给出了具体的数学表达式:
其中,$ x$ 表示信号,一般就是特征图,$i$ 表示时空位置索引,$f$ 计算 $ {x_i , x_j}$ 的相似度,$g$ 计算特征图在 $j$ 位置的表示,并且通过 $C(x)$ 进行标准化处理。写得挺好就是有点不好,看不太懂,举个例子就会好一些:对于输入的 $x$,在上图的计算方式(也就是 embedded Gaussion)下,出现了 $\theta,\phi,g$ 三个函数,其中 $g$ 就对应公式中的 $g$ 函数,而公式中的 $f$ 函数对应 $e^{\theta(x_i)^T\phi(x_j)}$,$C(x)=\Sigma_{\forall j}f(x_i, x_j)$,如果我们以此重写方程 $(1)$,将会变为:
并且,$\theta,\phi,g$ 也就是对应的 $Q,K,V$,具体来说有:
显然,对于 方程 $(2)$ 的前半部分,正是 $\rm softmax(Q^TK)$ 部分,这其实就是 SA 的一种简单的形式化表示,相对于标准 SA,缺少了对 $\sqrt{d_k}$ 的放缩,多了残差连接,是很小的改动。并且作者同样提出了很多种其他的 $f$ 形式,表明了 $\rm softmax$ 操作实际上在 NL 里并不是重要的,直接使用 $f(x) = \theta(x_i)^T\phi(x_j),C(x)=N$ 也可以取得很好的结果。
结果
对于结果,当然是很棒的,有着很高的 K400 得分,并且在 COCO 上 2D 分类也能通过 NL 提 1 个点左右。除此之外,作者做了很多的实验,分别探索了以 Res50/Res101 的 C2D/I3D 形式下,加入1/5/10 个 NL,采用Gaussian、Gaussian embed、dot-product、concatenation 的 NL 算法,在 K400 上测试了多组结果。在很大程度上超过了原始的 I3D。
最令人惊喜的是,对于 NL,我们可以仅使用 RGB 输入而舍弃光流,在仅使用 RGB 的情况下仍然超过了使用双流的 I3D,虽然 NL 也不是很廉价的操作,但是对比于光流已经改进了不少。

图中标灰的使用了 3 模态,相比于单模态的 NL I3D 优势太大,尽管如此也没有超过 NL I3D。因为此时的 I3D 还没有发以 ResNet 为 backbone 的结果,因此只比较了以 inception 为 backbone 的 I3D。
R(2+1)D
A Closer Look at Spatiotemporal Convolutions for Action Recognition 【视频动作识别】 CVPR2018
动机
在视频理解逐渐火热的时候,出现了一个尴尬的问题:使用 res151 在 sports-1M 上逐帧输入的情况下仍然得到了接近 SOTA 的结果。也就是即使不使用大家普遍认为的关键点,即多帧信息,仍然是很好的结果。
因此 FAIR 做了这个工作,说白了,就是将 3DCNN 拆分成对于空间的 2DCNN 和 时间上的 1DCNN,通过多方对比,证实了 3DCNN 还是有效的,并且以同样的参数取得了相比 3DCNN 更好的效果,是个大型消融实验现场,同样的还有 ConvNext,挖坑等填。
网络
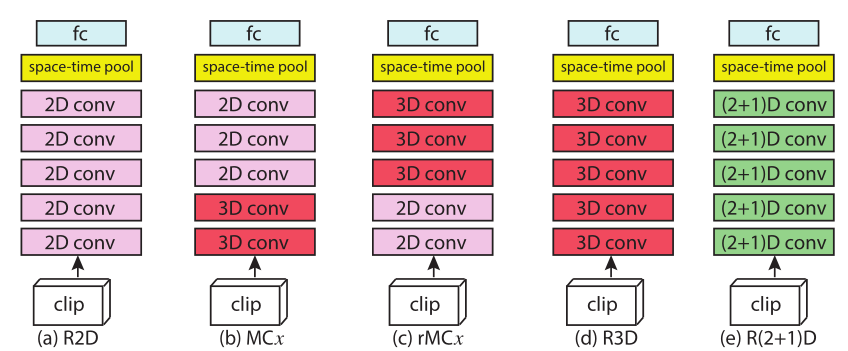
本文总共尝试了 5 种网络结构,分别从 2D,先 3D 后 2D,先 2D 后 3D,全 3D,全 R(2+1)D 五个方面做了测试,并且在输入帧的层次上尝试了 8 帧和 16 帧的输入,并且对比了 RGB 和 FLOW 以及两者结合的输入方式。在结果上,对比了 I3D 在 UCF-101,K400,sports-1M 上的结果,离谱的是完全没打过 I3D(打不过 I3D 不离谱,毕竟 I3D 巧夺天工,作者圆的很离谱,属于浑身上下只有嘴是硬的)
需要注意的时候,这些所有的网络使用的都是具有 5 个 stage 的 ResNet,具体来说,包括 res18 和 res34。
R2D & f-R2D & R3D
对于 2DCNN,有两种处理方式:1.将多个帧进行堆叠,对于 RGB 通道的图像,堆叠 L 帧,得到的输入通道就是 3L,接下来按照普通 2DCNN 做就行,2.将多个帧逐个输入,得到多个帧的独立特征图,然后经过顶部池化进行融合,其实没啥区别,R2D 就相当于在 f-R2D 的池化前面加一个 1x1Conv。
至于 3DCNN,本文表示:使用经典的 3DCNN 网络,相当单纯,甚至对标的是 2015 年的 paper。
MCx & rMCx
由于有这么一种说法:运动建模(即 3D 卷积)可能在早期层中特别有用,而在更高级别的语义抽象(晚期层)中,运动或时间建模不是必需的。因此本文探索了 (r)MC2-5 共 8 中结构。
R(2+1)D
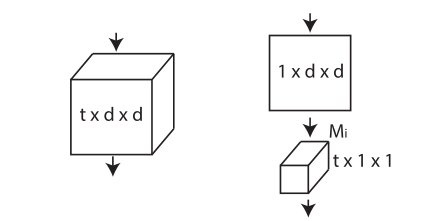
所谓的 R(2+1)D 其实只是将一个 txdxd 的 3D 卷积块拆分成先进行 1xdxd 的 2D 空间卷积,再进行 tx1x1 的时间卷积,在两者中间按照惯例加入一个 ReLU。在保证输入和输出的通道、维度一样的情况下,对于 R(2+1)D 实际上多了一个参数,就是选取的 2D 卷积核的个数。作者所谓“为了公平比较”,将通道数通过一个计算公式得出,保证 R(2+1)D 的参数量大约等于同层数的 3DCNN。
这种结构有两个好处:1.由于 ReLU 的非线性,整个网络的非线性程度将会扩大一倍。2.这种拆分的形式能够能加有利于网络的训练(第 2 条纯粹是结果导向的结论罢了)
参数量-帧数-准确度 对比
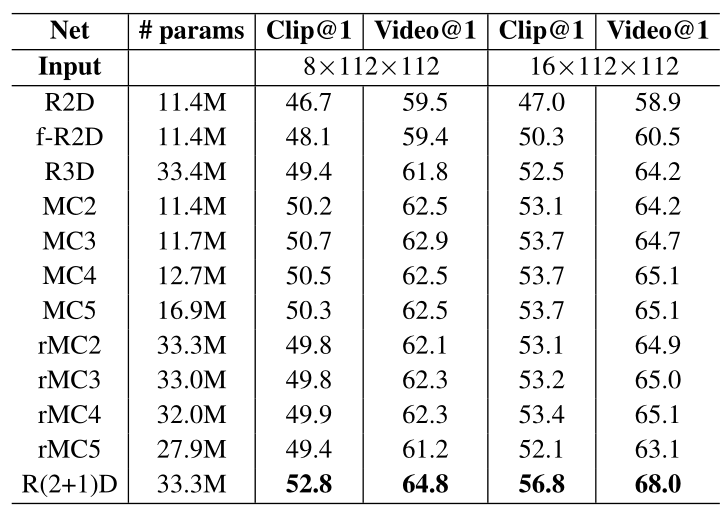
可以看出:1.3DCNN 真的很大,效果比 2D 确实好了一点点。2.R(2+1)D 效果确实比 3D 好了一点点。3.多帧输入确实比单帧好一点点。
这张图显示出的效果其实也没啥太大冲击力,比较对比的是 15 年的老方法,也没有太明显的超越。不过还是能看出 R(2+1)D 有些小优势,更深的 res34 相比于 res18 也更好一些。
结果
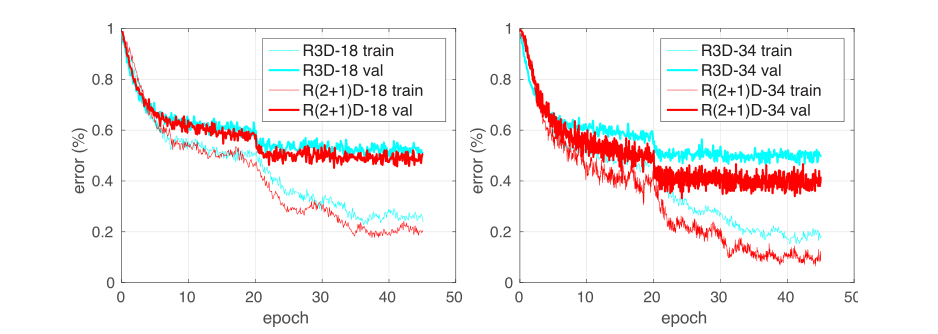
整体来说反正不如 I3D,也没啥好看的,但是有意思的来了嗷,在 UCF-101 和 HMDB51 上验证时,有这张图:

这张图中呢,显然 R(2+1)D 是不如 I3D 的,但是作者解释为:

他说自己不如人家 I3D,但是 I3D 用了 ImageNet 预训练,话里话外就是说 I3D 如果不用 ImageNet 预训练就不如自己呗,但是事实并非如此捏:

关于《 I3D 如果不用 ImageNet 预训练就不如 R(2+1)D》,不能说是有理有据,基本也是信口雌黄。当然,R(2+1)D 在思路上是很棒的,之后也有很多工作基于 R(2+1)D 开展,取得了比 I3D 更好的结果,只是这张图和解释,真是老太太钻被窝了属于是👴。
SlowFast
SlowFast Networks for Video Recognition 【视频动作识别】 ICCV2019
动机
在动物识别视觉信息时,有观察静态帧和动态帧的两种细胞,举例来说,对于 DOTA,静态帧即不会动的地图,动态帧即时刻在变化的英雄和小兵。并且这两类细胞有着一定的比例,基本上动态帧细胞占据全部数量的 20% 左右。基于这种直觉,FAIR 提出了两个同时进行数据帧的采样和卷积的网络结构 SlowFast,其总共有两个网络,是一种通用的网络结构,适用于多个 backbone,一个网络是 SLOW 网络,以较低的帧采样率通过较多参数的网络,另一个 FAST 网络则以较高的帧采样率通过较少参数的网络,网络之中进行横向连接。
创新
- 网络有两条互相补充的路径分别在高低时间分辨率下工作
FAST 分支中通道数较少,SLOW 分支中通道数较多
✔️用了细胞生物学的方式启发网络设计✔️
网络
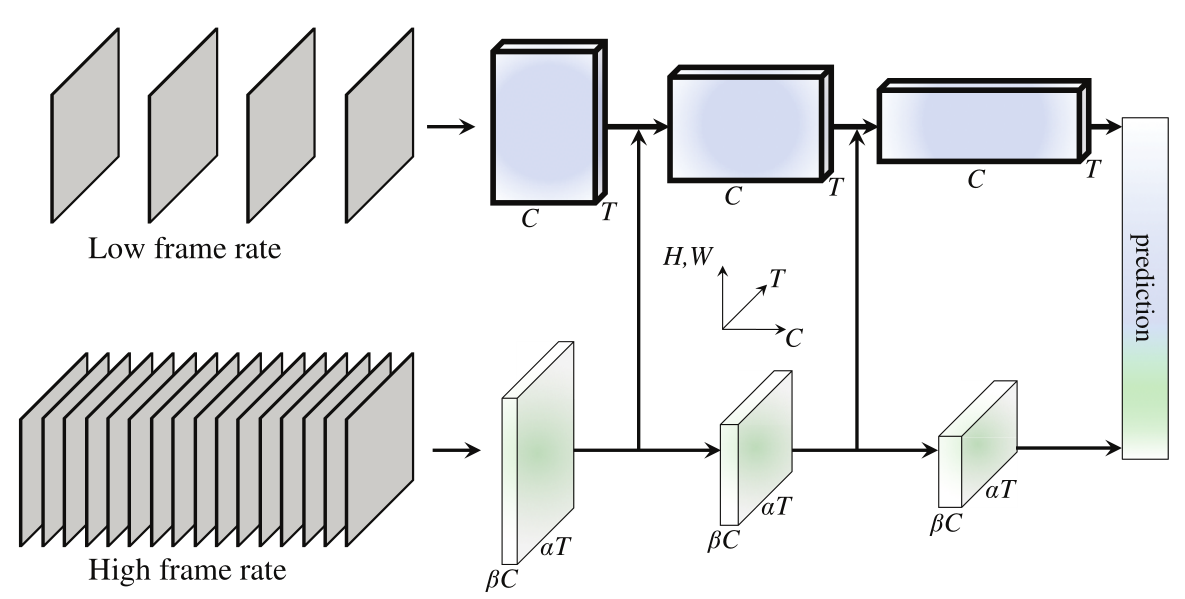
整体来说,这个网络可以适配多种 backbone,在本文中采用了 3D Res50 网络结构,两个网络分别采样,并且从 FAST 分支向 SLOW 分支进行横向连接,需要注意的是,SlowFast 在进行 3D 卷积时不进行任何时间方向的下采样。
SLOW 分支
对于 SLOW 分支,其采样率更低,具体来说是每 16 帧取 1 帧,最终得到 $T$ 个帧。其参数量更大,具体体现于卷积的过程中通道数更多,初始每个帧 3 通道,之后的特征图通道数用 $C$ 表示,且 $C$ 在不断变化。初始的图像大小为 $H\times W$ ,$H=W=224$。
FAST 分支
对于 FAST 分支,其具备更高的采样率,这里的高采样率相比于 SLOW 分支进行讨论,具体来说,是 SLOW 分支采样率的 $\alpha$ 倍($\alpha > 1 $,默认为 8),即最终采样得到 $\alpha T$ 帧。同时其具备更小的参数量,具体体现在于卷积的过程中参数量较少,即相对于 SLOW 分支,每个对应阶段的通道数都是其 $\beta$ 倍($\beta <1$,默认为 $\frac 1 8$),即每个对应阶段的通道数均为 $\beta C$。$H,W$ 和 SLOW 一致。
横向连接
由于在生物体内,动态细胞和静态细胞之间是信息共享的,因此在每个阶段结束之后理论上都需要将两个分支的信息共享给对方,但是这里作者通过消融实验证明了:从 SLOW 分支向 FAST 分支共享信息是没有提升的,因此只通过 FAST 分支向 SLOW 分支共享信息即可。
由于 FAST 分支的每个阶段的 $\rm shape=(N,\alpha T,\beta C,H,W)$,而对于对应的 SLOW 分支,每个阶段的 $\rm shape=(N,T,C,H,W)$,因此需要一个映射使他们 $\rm shape$ 一致,作者提出了三个可能的方法:
- 直接进行 reshape 操作,将 $\rm (N,\alpha T,\beta C,H,W)\to (N,T,\alpha\beta C,H,W)$
- 每 $\alpha$ 个帧抽取 1 个通道进行融合,得到 $\rm (N,T,\beta C,H,W)$
- 通过一个 3D 卷积层,$\rm Ks=(5,1,1),stride=(\alpha,1,1),padding=(2,0,0)$,通道数为 $2\beta C$ 得到 $\rm shape=(N,T,2\beta C,H,W)$
对从 FAST 分支变来的新特征和 SLOW 的特征进行相加或级联(❓通道不同如何相加❓)
ANSWER:通过阅读代码:slowfast/models/video_model_builder.py:149 可知,传参的时候有个 fusion_conv_channel_ratio 参数确定了输出到底是几倍的 $\beta C$,以及最终是直接级联 cat。
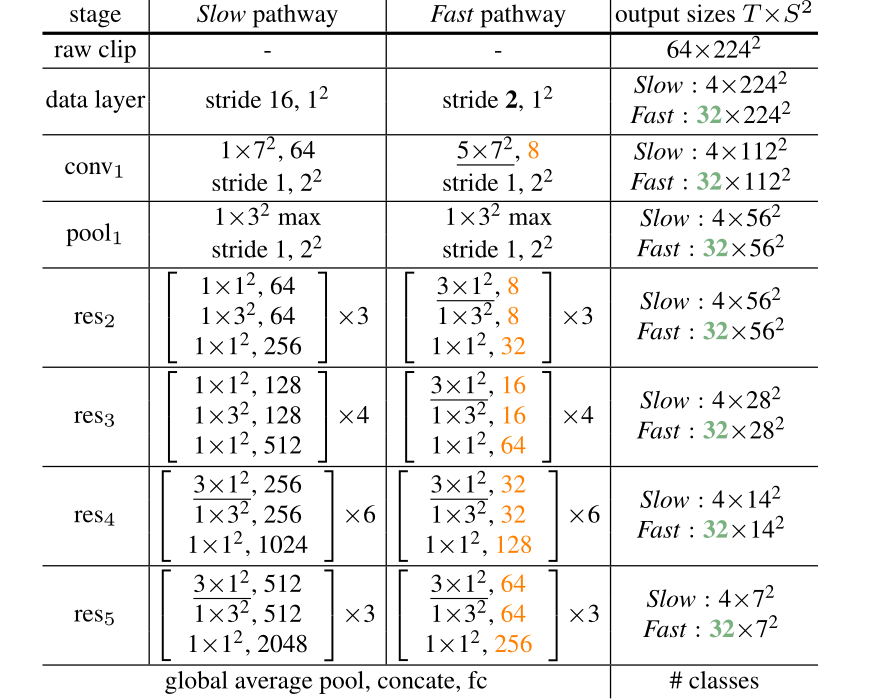
实例参数
作者给出了以 res50 为 backbone 的通道数、帧数、在不同阶段下的图像大小等参数信息,如下图:
结果
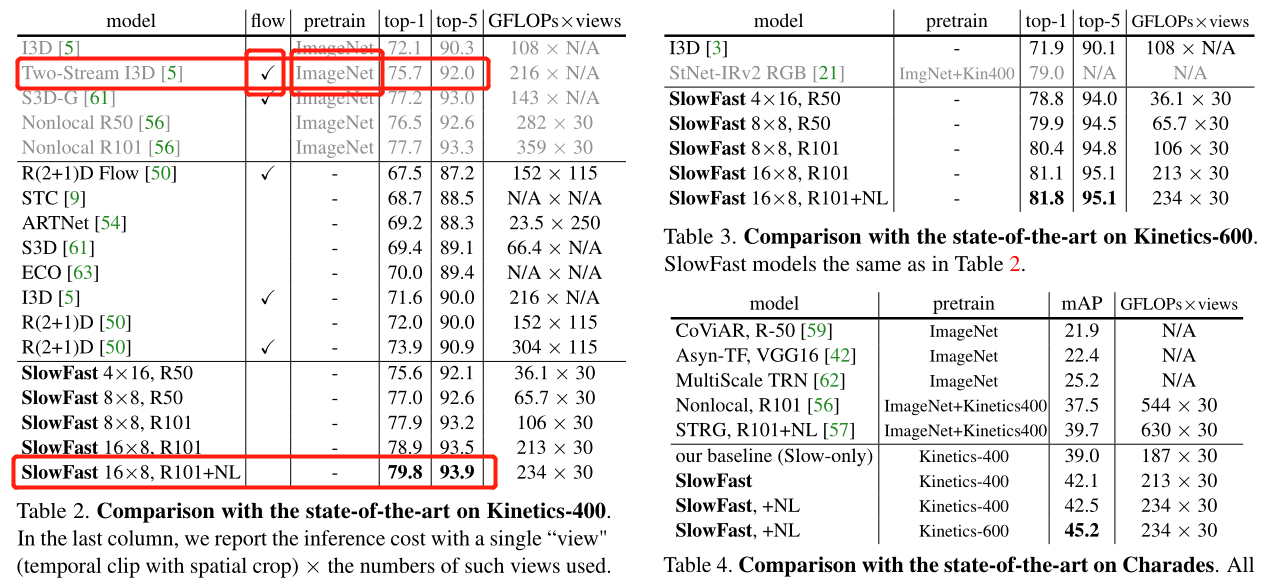
话不多说,真的无敌,特别是在 K400 上,就算是面对在 ImageNet 上预训练并且使用光流的 I3D,基本也是完虐,甚至不加 NL 都超之前的 NL R101 预训练模型,而这个 NL R101 其实是 KaiMing 的上一个 SOTA,在刷新记录这方面有种博尔特的感觉。
VTN
Video Transformer Network 【视频动作识别】 ICCV2021
⚠️⚠️⚠️⚠️⚠️
从这里开始一些工作出现于 2021 年,因此这些 2021 年的工作之间并没有互相比较,仅对比了 SlowFast
⚠️⚠️⚠️⚠️⚠️
创新
- 使用 transformer 结构代替了 3DCNN,提出的网络对 full-video 更加友好
- 使用了 LongFormer 作为时间网络
网络
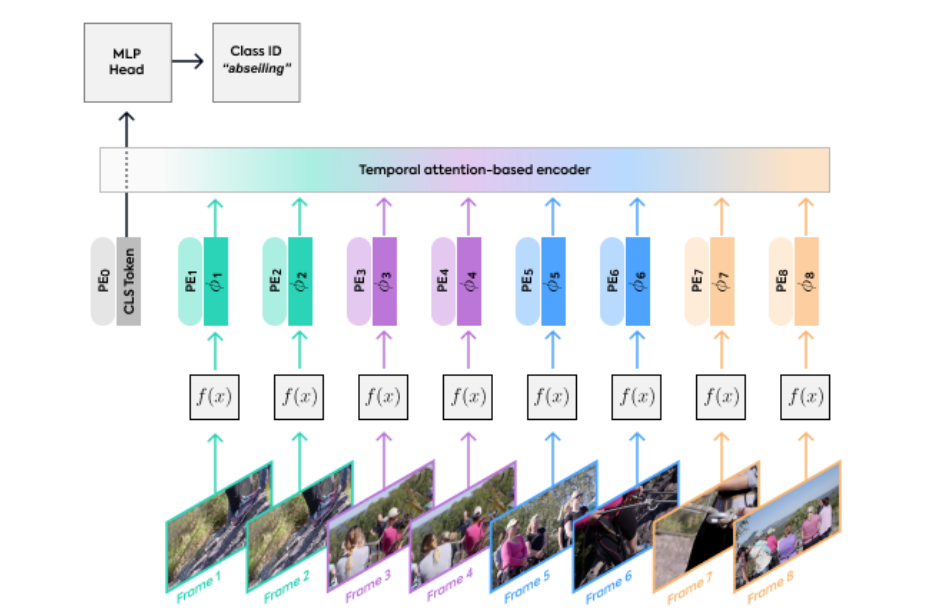
这个网络结构图非常清晰,只需要简单的解释即可,但是⚠️这个图居然不是矢量图⚠️,离大谱,放大之后就糊的一批。这也能发 ICCV 🤷❓网络由三个部分组成:空间部分、时间部分、分类头,也就是分别对应 $f(x)$,Encoder,MLP。分别介绍这前两个部分,MLP很普通,不再赘述:
空间网络
这里的空间网络是一个通用的网络结构,这里可以是任何一个能够提取特征的网络作为 backbone,无论是 CNN 还是 transformer。本文中尝试了 Res50/101,VIT,DeiT 三种骨干网络作为空间网络,并且分别探索了是否预训练、以及是否冻结参数进行训练的差别。最终实际上各种选择差别有但不大,整体来说最好的是使用 VIT-B 作为 backbone 的网络,并且基于 ImageNet-21K 预训练,在训练的过程中进行 FT(符合直觉)。
时间网络
在空间网络提取出特征图之后,特征图首先合并 PE,再经过一个 Longformer 网络,同时通过加入 CLS 标志位的方法进行分类。同时作者探索了输入视频帧的跨度和数目问题
首先对于 PE,作者提出了三种不同的 PE 方式:1.使用可以学习的编码,以输入的索引作为输入学习一个可变的编码,2.使用固定的编码,具体参考 DERT,3.不使用任何位置编码。在作者的实验中,这些不同的编码方式在准确率上仅产生了不到 1% 的差别,其中最好的方式居然是不编码,并且 shuffle 之后的结果均更好。以结果论的方式前推,这可能是因为视频的多帧之间的先后顺序并不重要,倒放的视频表示的同样是一个动作,甚至乱序播放的视频也不影响其本身的语义。
对于 Longformer,其本质上是基于窗口的 transformer,是针对 NLP 领域提出的网络结构,目的也是解决 $O(n^2)$ 复杂度的问题,其相对于原本的注意力窗口提出了如下三种不同的窗口计算方式。对于 $(b)$,是指每个位置仅计算和自己左右各 $\frac 1 2 w$ 窗口内的位置的注意力($w$ 是窗口大小),对于 $(c)$,即每个位置向左右各计算 $\frac 1 2 w$ 个位置的注意力,对于 $(d)$,这里表示的是带有 CLS 的情况,CLS 需要对全局进行建模,其他位置较多仅关注 local,少部分位置关注 non-local。
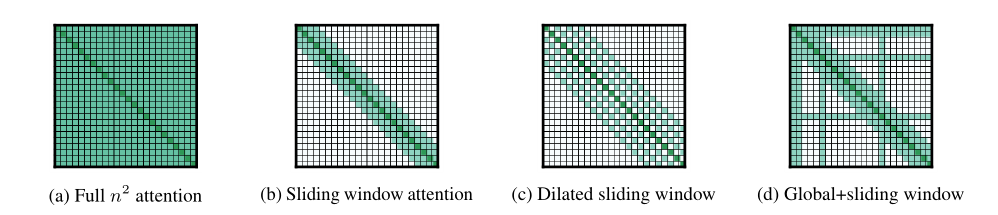
因此,Longformer 可以进行高复杂度的全局建模,并且更适配 CLS。在这里作者尝试了多层的 Longformer,有意思的是,在 1,3,6,12 层中几乎没有差别,甚至 1,3 层 MHA 的效果是最好的。具体的配置包括在不同情况下的 dropout 和 窗口大小、MHA 内隐空间维度详见论文。
由于 Longformer 可以进行全局性质的建模,相比于 3DCNN,自然有更好的全局信息能力,因此相比于传统的 multi-view 输入(即对小片段视频进行帧采样),Longformer 也许可以使用 full-video 输入(即对整个视频进行帧采样,自然帧率会更低),对于结果来说,所有的传统方法,full-video 都比 multi-view 效果明显降低,而对于 VTN,基本上 full-video 和 multi-view 完全一致,也没有什么提升。
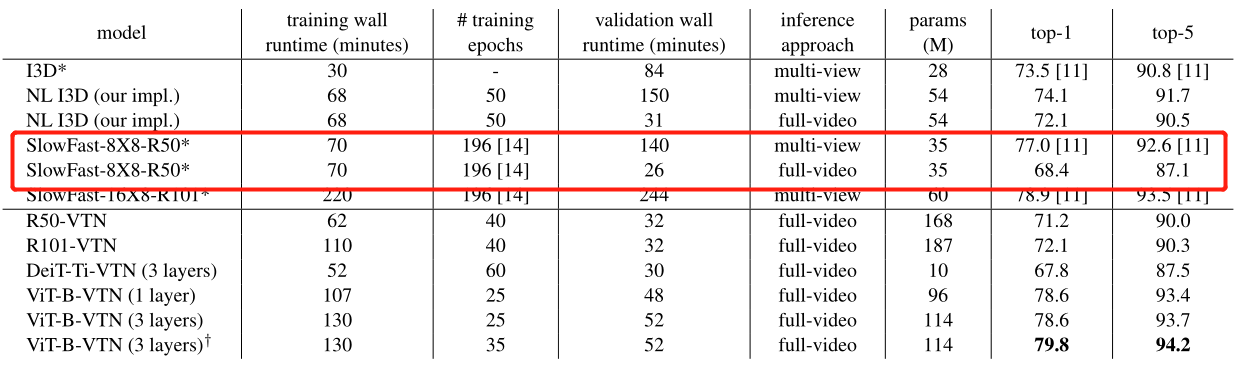
结果
就本文来说,是对 transformer 简单迁移,基本就是组合了 VIT 和 Longformer,分别作为空间网络和时间网络,效果上平了 SlowFast(这个表上的 SlowFast 没有加 NL,加了 NL 之后的准确率是 79.8 & 93.9),不过毕竟是 transformer,参数量大约是 SlowFast 的两倍。同时本文做了很多的消融实验和思考,包括长时间片段建模的好坏、不同位置编码方式的好坏、预训练后微调产生的优势等等,基本来说,作为第一批应用 transformer 到 video 的工作之一,探索的点还挺全的。
Timesformer
Is Space-Time Attention All You Need for Video Understanding? 【视频动作识别】 ICML2021
创新
- 使用 transformer 结构代替了 3DCNN,提出的网络对 full-video 更加友好
- 探索了多种时空组合的 3D VIT 形式
网络
其实对于 Timesformer,因为这篇工作和 R(2+1)D 同为 FAIR 出品,甚至二作就是 R(2+1)D 的一作,因此风格和 R(2+1)D 非常像,基本上是实验性的工作,并且同样提了五种实验性的网络结构,甚至提网络也是同样的思路:3D 开销大?拆!
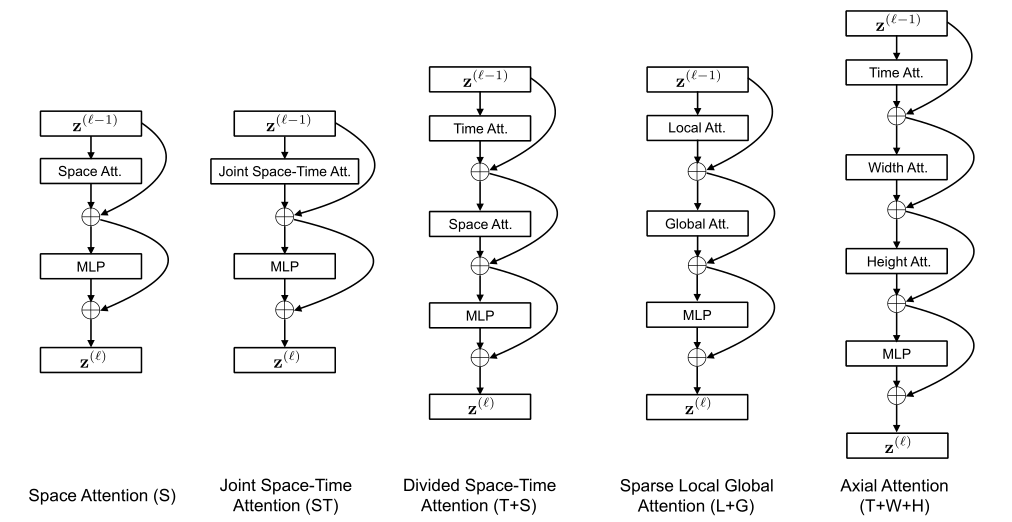
这五种网络结构实际上对应了五种不同的对于输入 clip 的注意力计算方式,作者为了更好地解释这五种注意力计算方式,还给出了下面这张图,下面这张图表明了某个 patch 在各种注意力计算方式下具体和其他 clip 中的哪些帧进行了注意力计算。该说不说,这个图画得挺直观的。

S
这是一种 baseline 的计算方式,对于输入的 clip,就按照 VIT 的方式逐帧进行处理,在注意力图中,每个 patch 只和同属于同一个时间维度的 patch 计算注意力。这种计算方式开销和 VIT 一致,但是效果自然不会太好,实际上这里的效果在测试的时候在 K400 上展现出了还不错的效果,但是在 SSv2 上效果很差,这是因为 K400 中的动作并不太依赖时间跨度,而 SSv2 更依赖时间跨度。
ST
同上,这也是一种 baseline,只不过在这里按照 3DCNN 的方式进行简单的扩张,每个 patch 和当前 clip 中的所有 patch 都计算自注意力,这种计算方式理论上能够取得最好的效果,毕竟对时空全都做了注意力计算。就结果来说,ST 的计算方式确实和 T+S 一致取得了最好的结果。但是这种方式复杂度太高,对于稍微长一点的 clip 就会爆内存。
T+S
这种方式就是 R(2+1)D,即先做时间维度上的注意力,再做空间维度上的注意力,在注意力可视化图中刻意看到,蓝色的 patch 首先和绿色的 patch 进行了自注意力操作(需要注意这里虽然只列出来了三个相邻帧,实际上是对 clip 内的所有帧都计算时间注意力的),接下来再和红色的 patch 进行自注意力计算。这种方式按照直觉也是最好的,因为平衡了时空注意力计算和计算复杂度。
L+G
所谓 L+G,指的是 local+global,即对于全部时空 patch 都计算注意力开销太大,因此先计算对当前 patch 离得近的,这里只考虑空间的近,也就是说蓝色 patch 会计算和粉红色、黄色 patch 的注意力,然后再和紫色 patch 进行计算。这种方式相对于 ST 在某种程度上也降低了计算复杂度,但是在空间上的效果可能还不如 baseline,而众所周知,时间信息固然会加点,空间信息是更加重要的,因此结果并不好。
T+W+H
即在三个维度上分别先后做自注意力,这样操作使得注意力关注的范围小了很多很多,虽然计算复杂度降下来了,但是对空间信息的过分不关注导致了降点。
结果
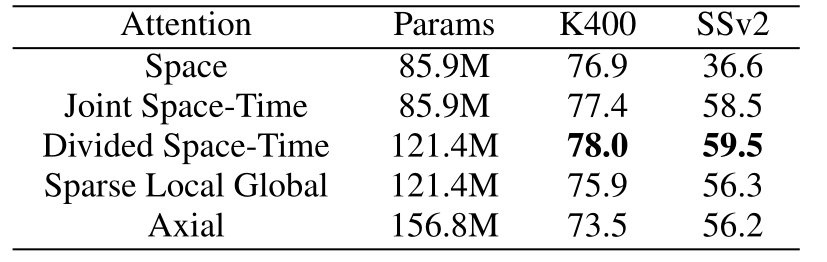
可以看出对于单帧自注意力,K400 上效果还不错,但是 SSv2 上效果很差,这是因为数据集之间的区别。至于 S+T 的效果最好是意料之中的。
像是所有的 transformer,因为更大的感受野,因此对于 full-video 的支持更好,同时和其他的 transformer 工作一样,Timesformer 也提出了 S-HR-L 多种参数形态,在最大参数最高帧率下,Timesformer 在 K400 达到了 80.9,算是超越了 SlowFast R101+NL。
MViTv1/2
Multiscale Vision Transformers 【视频动作识别】 ICCV2021
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection 【视频动作识别】 CVPR2022
创新
- MViT
- 使用多尺度的方式处理图像,得到不同感受野的信息(此研究独立于 SwinT,同时实验表明这种方式能够更好地学到时间偏移)
- 通过扩展多阶段同时减少各阶段序列长度的方式,减少了很多计算量
- MViTv2
- 对 MViT 进行了改进,加入了相对位置编码
- 为了消除池化操作产生的信息消失,加入了残差连接
- 将 MViT 应用于了基于 FPN 的 mask-RCNN
网络
- MViT
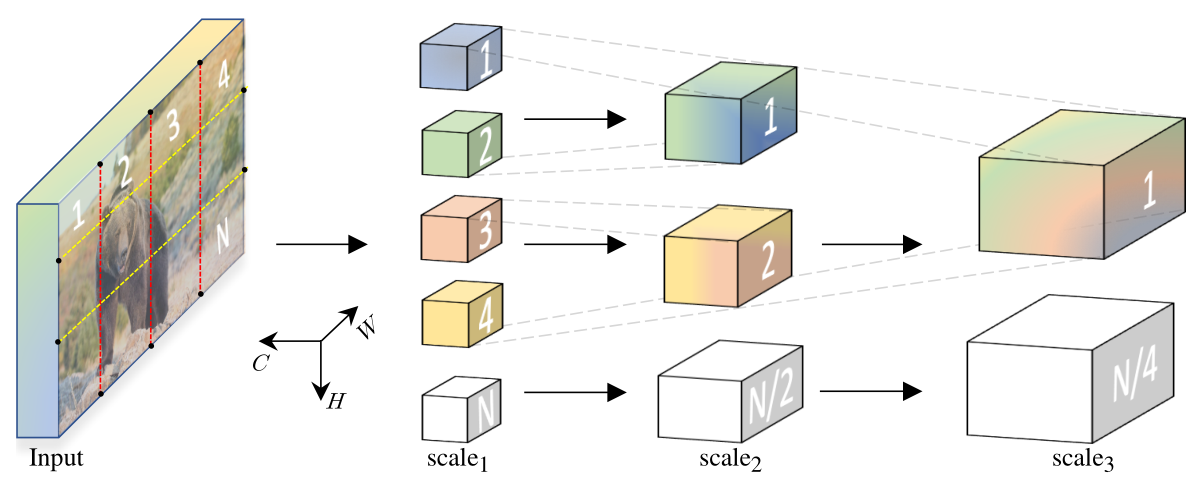
前向过程
整个 MViT 的前向过程是基于 stage 的,也就是在不同的阶段有不同的深度和具体注意力计算的维度设置,对每个阶段,作者提出了一种新的计算多头自注意力的方式 MHPA($\rm MultiHeadPoolingAttention$)。这个层会将输出逐层进行降采样,因此最终的输出比原输入的 shape 要小,类似 swinTransformer。
首先对于输入视频进行帧采样:得到 $(D,T,H,W)$,其中 $D$ 表示通道数,$T$ 表示帧采样数,然后打 patch 并加入 PE,这里的 PE 是绝对 PE,打 patch 的时候每个 patch size 为 4x4,这是因为这里的 patch 是 3D 的,太大了会导致计算复杂度较高。基本上就是 3D 版本 VIT,但是没有用学习位置编码,这其实是一个缺陷,因为这种位置编码破坏了图像的先验知识平移不变性,在 MViTv2 中得到改进。
接着通过多层的 MHPA+MLP,这里的 MHPA 会进行降采样,对于输入 $X\to(L,D)$ 会降低序列长度 $L$ 并且增大 $D$,因此通过 MHPA 之后的 $X’\to(\hat L,2D)$,之后再通过 MLP,多次循环 MHPA+MLP 即可得到最终输出,在多层的输出中,每层的 output shape 由下图给出。

这里稍微需要注意的是,由于每个 MHPA 都会降采样,而每一个 stage 都会执行多次 MHPA,因此实际上在执行时每个 stage 只有第一次执行 MHPA 的时候会进行降采样,其他的 MHPA 中的池化卷积核都是 1x1x1。
MHPA
MHPA 简单来说就是在计算出 $Q,K,V$ 之后加入一个池化层从而使其维度下降,具体来说 MHPA 如下图所示:
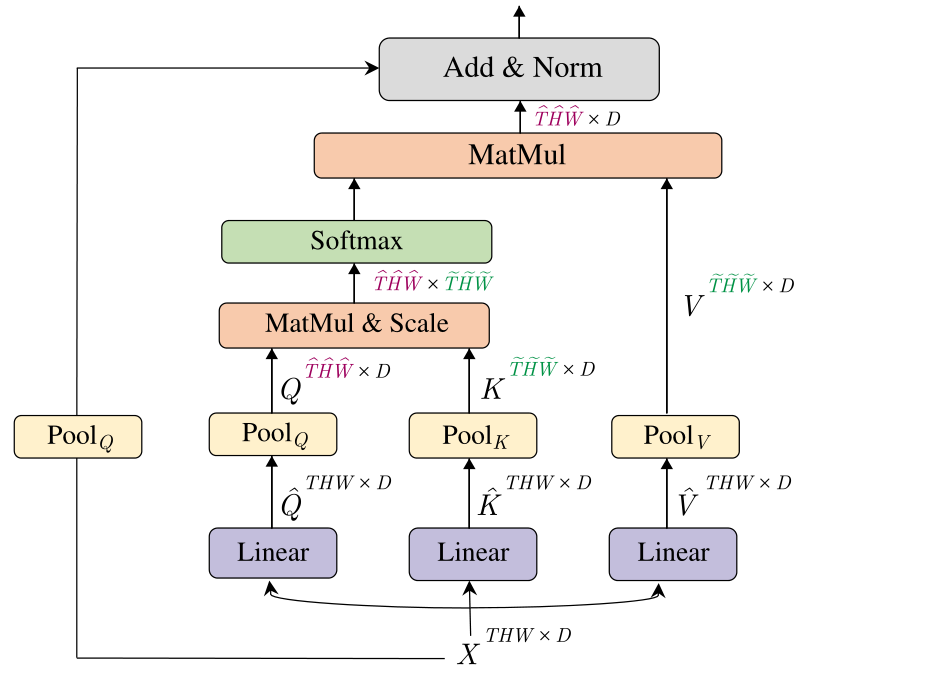
对于输入 $X\to(L,D),L=THW$,首先正常获得 $\hat Q,\hat K,\hat V\to(L,D)$,接着就是关键的池化操作,即将 $\hat Q,\hat K,\hat V$ 都经过一个 池化层进行降采样,计算公式很简单,即 $\hat L = [\frac{L-K+2P}{S}]+1$,于是得到的 $Q,K,V\to(\hat L,2D)$,具体来说对于 $\hat L$,其中的 $(\hat T,\hat H,\hat W)=(T,\frac H 2,\frac W 2)$,同时通道数扩大了二倍,这是遵循 CNN 的设计法则:当降采样到原 size 的 $\frac 1 4$ 时,通道应该扩大一倍。之后的计算和 VIT 保持一致,同时加入了残差连接,但是由于此时的输出已经变了,所以对 $X$ 也进行一个 pooling 再连上去。这里其实也是一个缺陷,因为对 $X$ 的池化显然会损失相当多的信息,残差连接的效果会变差,在 MViTv2 中得到改进
需要注意的是池化本质的目的是降低整个 MHPA 之后的 shape,而计算过程中 $QK^TV\to(Q.shape[0],D)$ 实际上对于 $K^T\times V$ 过程里的 $\rm K.shape[1]=V.shape[0]$ 具体值无所谓,也就是说其实只需要更改 $Q$ 的第一个维度,即仅对 $Q$ 进行 pooling 即可使维度降低,对 $K,V$ 理论上不需要进行 pooling,但是实验表明对 $K,V$ 的池化甚至更加重要,并且为了能更好地适应不同状态下的池化,这里令每个 stage 的每一次 MHPA 都对 $K,V$ 进行池化,并且这些池化卷积核在仅在同一个 stage 内相等,即 $\Theta_K=\Theta_V$。
- MViTv2
⚠️对于结合 FPN-mask-RCNN 做目标检测,因为任务和研究方向毫不相关,因此只看 MHPA。
MHPA improved
改进后的 MHPA 基本就是按照上述 MViT 中的改进点加入了两项改动:1.加入相对位置编码,即在 $QK^T$ 之后加入相对位置编码,以此来保证相对位置一致的 patch 之间不会因为绝对位置编码产生不同的影响。2.加入残差池化连接,即对池化之后的 $Q$ 进行残差连接至 $Z$,消融实验表明残差连接是有效的,加入这项改进的原因是对 $K,V$ 的池化操作实际在同一个 stage 的每一步都在执行,而 $Q$ 只在第一步执行了池化。
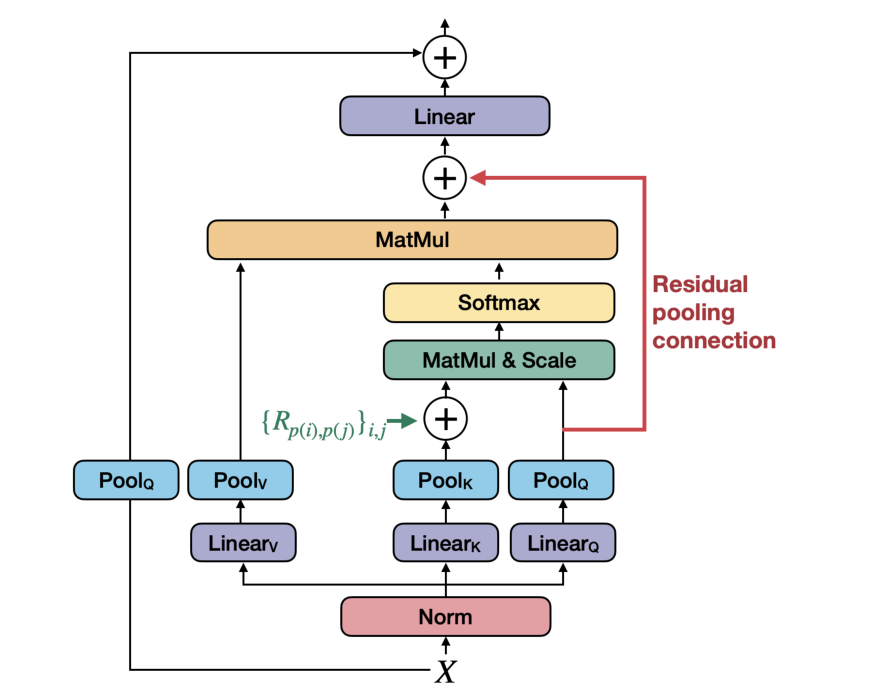
对于相对位置编码,具体来说,该编码是可学习的,记其为 $R_{p(i),p(j)}$,其中 $p(i),p(j)$ 分别代表在时空维度内 $i,j$ 下标的位置,$R$ 即为这两个位置之间的 PE。结合方式为:
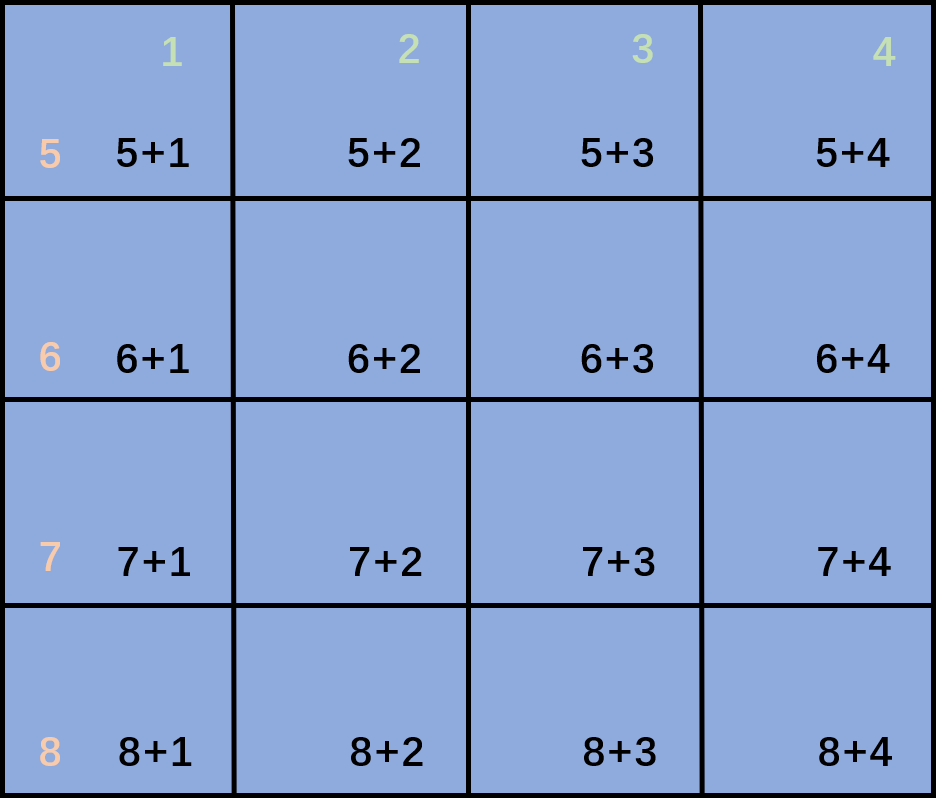
但是这种计算方法由于需要考虑三个维度的位置,具体来说计算复杂度为 $O(THW)$,因此作者尝试将其进行分解,三个维度分别计算再相加,这种方式算出的结果或许会有重复但是不影响相对位置的思路。具体的分解方式为 $R_{p(i),p(j)}=R_{h(i),h(j)}^H+R_{w(i),w(j)}^W+R_{t(i),t(j)}^T$,这个公式很明确,简单以下图举例,在下图中展示了一种简单的 $HW$ 相对位置编码示例,在这里只需要计算两个维度的位置编码,具体的位置编码使用横纵坐标求和。具体的实现代码稍微有点多,处理上中规中矩但比较复杂,详见 github_repo:MViT/mvit/models/attention.py:45。
对于残差池化连接,具体来说就是 $\rm Z=Attn(Q,K,V)+Q$,实现起来也就几行代码。
结果
- MViT
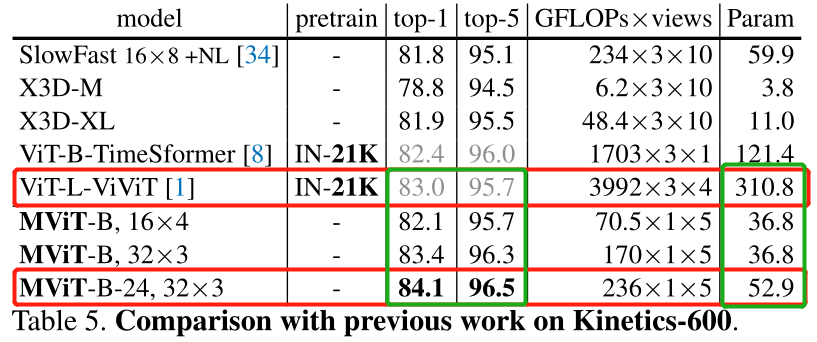
结果随便举个在 K600 上的测试对比,可以看出来简直无敌,且不说超了需要基于 IN-21K 预训练的 ViViT一个点多,甚至参数量和 flops 都是数量级级别的下降,是非常友好于复现和自主训练的,这要多多归功于每过一个 stage 之后的序列长度都会减少。由于此工作独立于 swinTransformer,其实其效果是不如 swinTransformer 的,但是在 MViTv2 还是超过了 swinTransformer。

除此之外这个结果也很大程度上证明了这项工作的有效性,通过 shuffle 输入的方式分别训练 MViT 和 VIT,可以看出 MViT 效果大打折扣,而 VIT 几乎没有变化,而视频的前后性是一项特别在视频领域的知识,显然 VIT 没有利用上这一知识,而 MViT 学到了这项知识。
- MViTv2
这里做了物体检测、图像分类等多种实验,但是只看 video K400 的(毕竟只有 video 和 HR 有点关系)
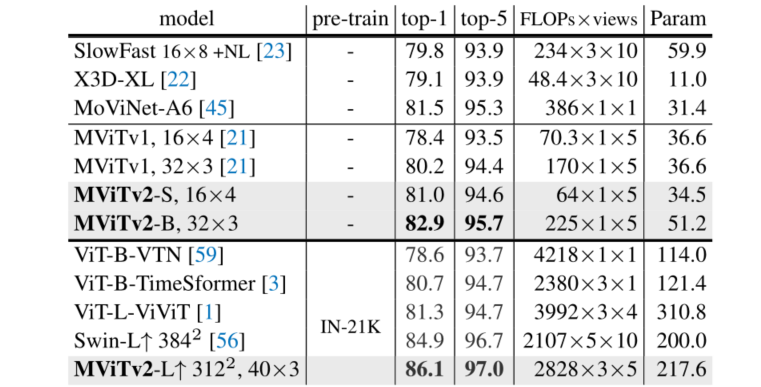
对比 MViT 的结果,这里大致提了两个点左右,这说明提出的两点改进是有效的,并且参数量和计算量甚至还降了一点点。至于更大的模型,在不经过预训练的情况下明显超过了 swin,注意这里的 Swin-L 是下一篇 paper Video Swin Transformer。好像顺序反了,MViTv2 更好一点呢好像 😅
Video Swin Transformer
video swin transformer 【视频动作识别】 CVPR2022
在视频领域有 ViViT,Timesformer 等工作珠玉在前,MSRA 之前又有一篇绝对领跑级别的工作 swinTransformer,毫无疑问 MSRA 会将其迁移到视频领域,于是有了 video swinTransformer,看名字大致就知道干了什么,除了效果好、实验多之外没有可圈可点的地方,简要介绍一下本文的 3D 处理。
网络
前向过程
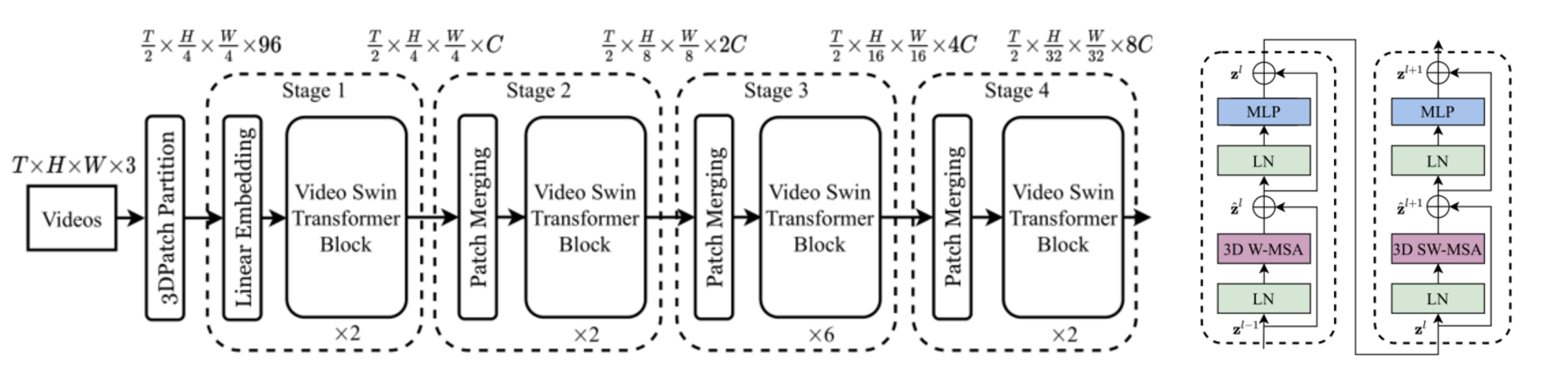
基础的网络完全接近于 swinTransformer,基本上仅在细节处有所不同。大致可以分为 embedding,backbone,head 三个部分。
embedding 具体来说,采样之后的 video 为 32x224x224,即 $T\times H\times W\times 3$,在打 patch 的时候每一个 patch 的 size 为 $P\times M\times M$,标准 VST 里面是 2x4x4,每个 window 具有 8x7x7 个 patch。
在经过和 swinTransformer 一样的打 patch 和线性投射层之后就分别通过 4 个 stage,后三个 stage 先进行 patch merging 再通过 VST 的 transformer 块,最后输出得到 $\frac T 2\times \frac H {32}\times \frac W{32}\times 8C$ 的输出,这里的输出是具备语义信息的表征向量,接下来需要再经过一个 head 网络融合这些 3D 信息,作者使用的是 I3D。
网络模块
对于 transformer 块,整体来说由上述网络图可以大致看出和 swinTransformer 基本一样,只有 3D W-MSA 和 3D SW-MSA 多了 3D,具体来说,3D W-MSA 将得到的 tokens 分成不同的 window 进行分窗口的独立自注意力计算,然后进行移位,3D SW-MSA 计算各个窗口之间的自注意力,大致过程如下图。
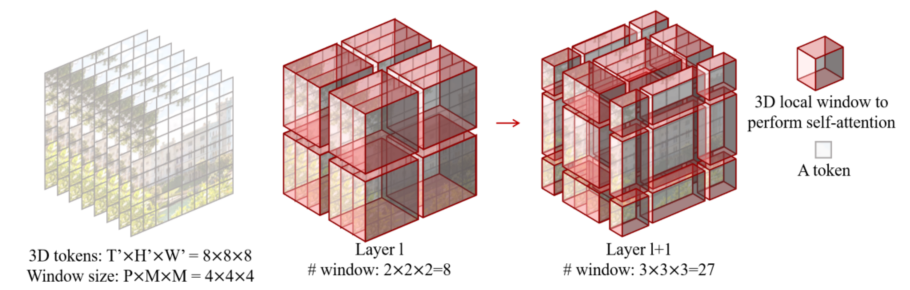
在移位之后会遇到和 swinTransformer 一样的问题,也就是计算量过大,在 3D 的情况下按照如下操作进行 cycle shift。

对于 patch merging,结合上述移位操作的图,也就是对每一个 $T$ 维度进行和 swinTransformer 一样的降采样操作。
实现细节
相比于 2D 版本的 swinTransformer,3D 模型的训练更加复杂和困难,而为了解决这个问题,本文采取了和 I3D 思路基本一致的初始化方法。具体来说,是对于已经经过预训练的 swinTransformer,embedding层输入的 shape 时间维度为 2,因此将权重直接复制两次,然后每个值乘 0.5;transformer 块中输入 shape 时间维度为 $2P-1$,因此将权重直接复制 $2P-1$ 次。两个复制一个做平均,另一个没有做,各有各的理由,反正都是结论倒退的,看个乐就得了。
结果
本文做了很多消融实验,意图按照之前的 ViViT、VTN、Timesformer 等网络的设置改进 VST,当然结果是改了之后也不如本身,不然就是改完之后的是 backbone 了。
对于不同时空注意力设计的消融实验如下图,本文共设计了三种不同的注意力形式,其中 joint 是 backbone 的默认形式,split 是在 2D swinTransformer 中的 MSA 之后接两个时间注意力层,factorized 是在同样的位置加一个时间自注意力层。
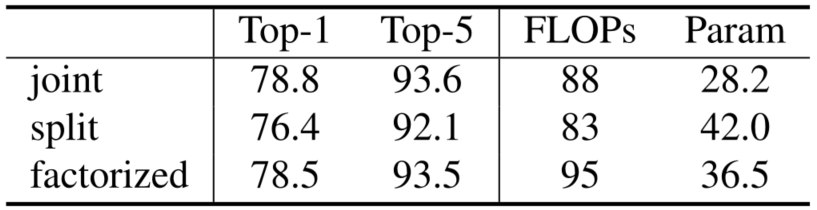
对于时间维度的值的消融实验不展示了,结论是无论是帧采样还是窗口大小,越大的时间维度就意味着越好的效果。同样的还有 3D SW-MSA 的消融实验,结论是无论是时间 shift 还是空间 shift 都不可或缺。
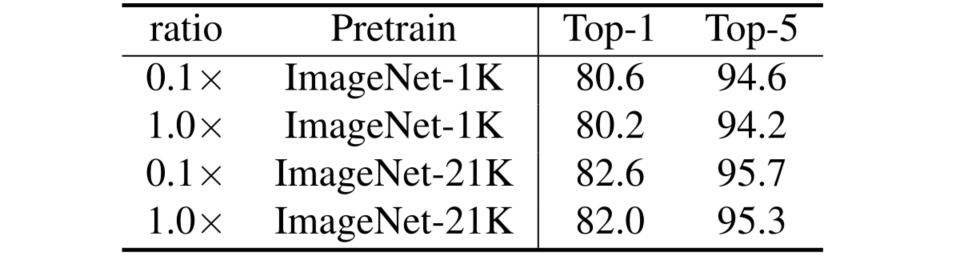
对于 backbone 和 head 的学习率的消融实验如下图,本文发现了由于 head 随机初始化,对于预训练参数初始化的 backbone 最好使用更低的学习率训练,具体来说,本文尝试了 $\rm ratio=\frac{lr_{backbone}}{lr_{head}}=1/0.1$,发现 0.1 更加合适,然后给了个结论倒推的原因,即:在拟合新的视频输入时,主干会慢慢忘记预先训练好的参数和数据,从而更好地泛化。
和 MViT 一样,本文也测试了 shuffle 之后的结果,不过他既然测了这个,结果肯定是 shuffle 之后效果变差了,这样才能说明自己学到了时间信息。
具体到网络的结果,本文最高的 Swin-L 在 200M 参数、2107 Flops 、IN-21K 预训练的情况下达到了 84.9,整体上由于 ViViT,不过很快就被 MViTv2 超了。