VideoGPT: Video Generation using VQ-V AE and Transformers
【视频生成】【arXiv2021】【paper】【code】
摘要
本文使用 VQVAE 作为整体结构,第一阶段编解码器为 Conv3D,不使用 GAN 策略进行训练。同时采用 iGPT 作为第二阶段的 transformer 结构,直接对 video 进行编码,同时提出了一些训练 VQVAE 的经验,总结来说或许是趁着 iGPT 出了一个 paper,整体视觉效果和现在已经完全比不上了。
概览

创新
- 使用带有时间注意力和位置编码的 Conv3D 结构作为 VQVAE 第一阶段的编解码器
- 采用 iGPT 作为第二阶段的 transformer 结构
tricks
- 使用 EMA 更新 codebook 可以更快地收敛(经验发现)
- 训练之前将所有的图像数据进行归一化(经验发现)
- 在第一阶段训练时使用编码器输出随机复制重启 codebook(参考了20 年的 Jukebox)
- 计算 loss 之前首先对 codebook 进行 l2norm(和 improved VQGAN 思路一致)
网络
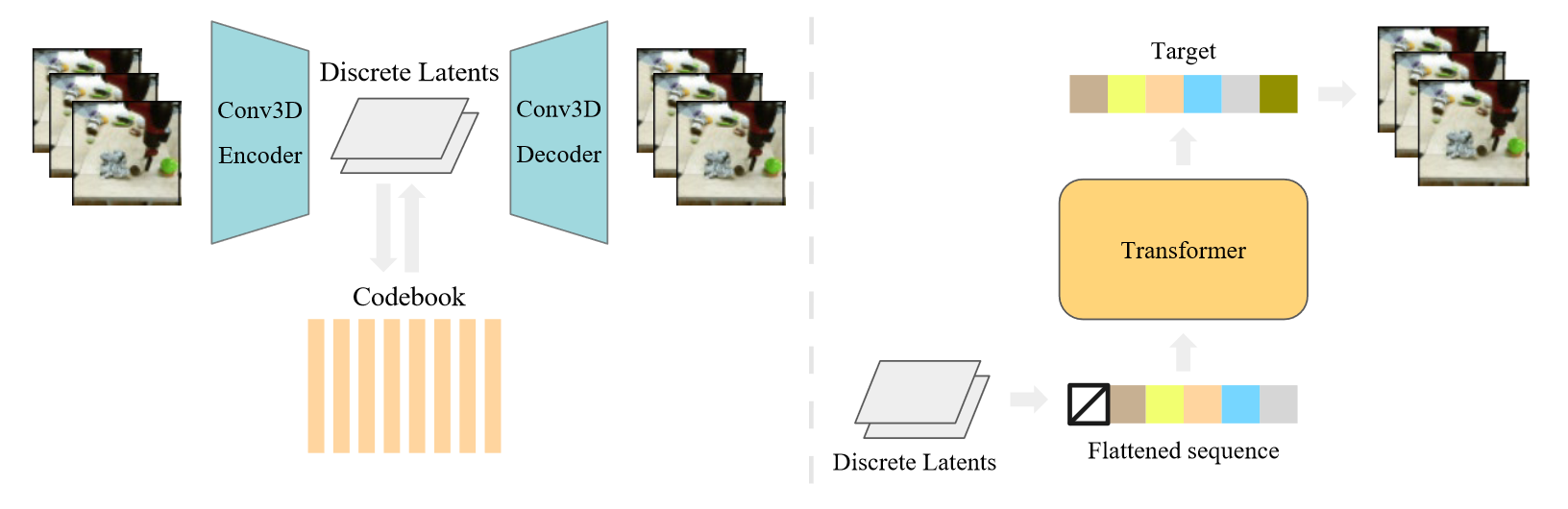
本文的前向过程非常简单,整体来说完全参考 VQVAE 的设计,第一阶段将编解码器改为自己设计的 Res3D 结构,直接对 video 进行编码,第二阶段采用 iGPT 作为 transformer。
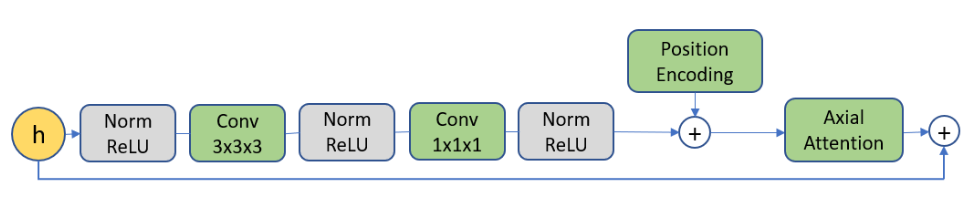
对于第一阶段的编解码器,其架构由一系列三维卷积组成,在时空上进行下采样,然后是注意力残留块,具体来说如下图所示,其中的 Axial Attention 参考 Ccnet。对应的,解码器完全反向编码器。
对于第二阶段的 iGPT,其实目前常用的自回归架构基本和 GPT2 没啥区别,只不过需要区分 BERT,而这篇文章只提到自己沿用了 iGPT 的结构,但是 iGPT 在 GPT2 和 BERT 的两种做法(最大似然后一个与中间一个)都做了探索,不确定这篇文章用的什么(有 code,但是感觉没必要看)。
损失
也就是普通的 VQVAE 训练时候的 loss,效果不好是意料之中的,根据经验,在不经过 GAN 对抗的情况下,仅依靠 MAE/PSNR 等指标进行优化会导致重建更加趋向平滑。
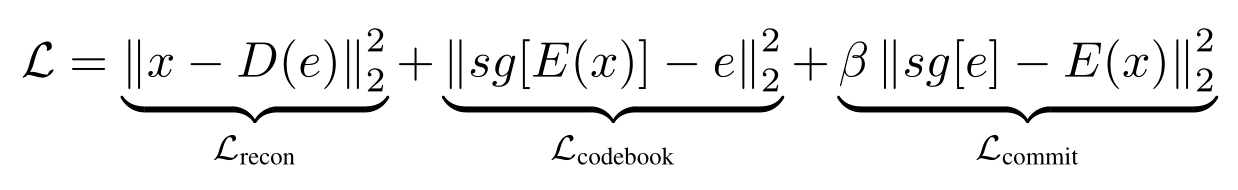
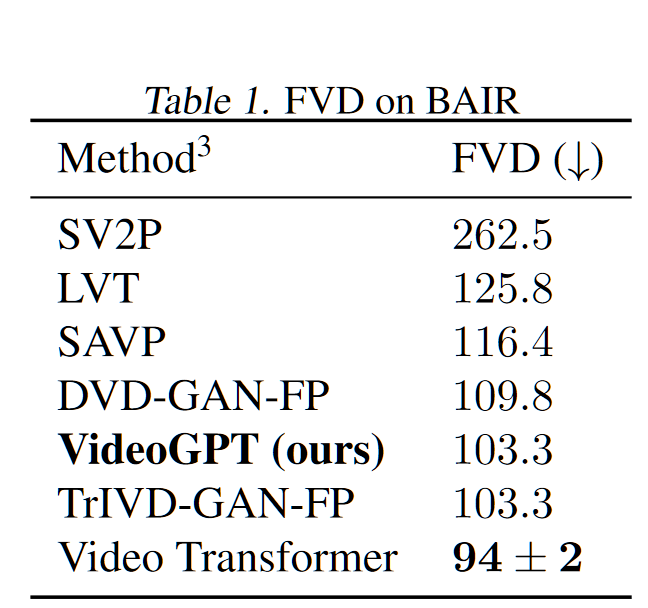
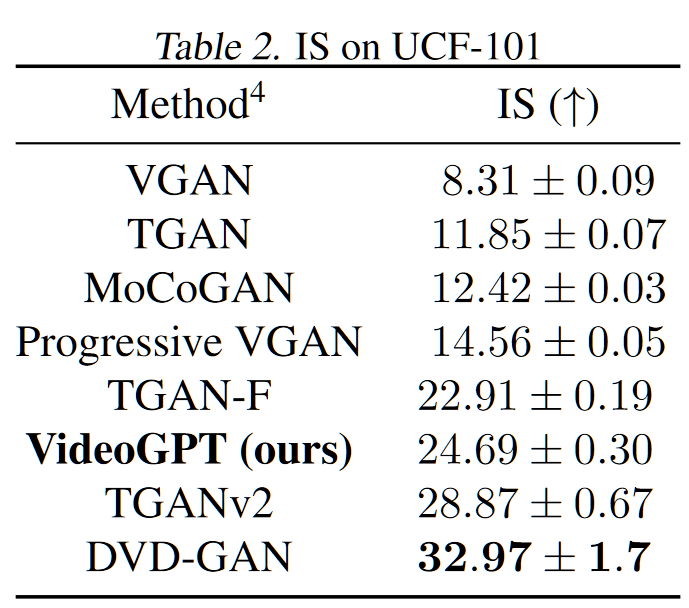
结果
在不同数据集上的 FVD:
 |
 |
|---|---|
目前看来糊的离谱的 video:
