StyleVideoGAN: A Temporal Generative Model using a Pretrained StyleGAN
摘要
本文使用预训练的 styleGAN 为基础,采用类似 pSp 的架构进行 $\mathcal W+$ 空间的视频序列监督,同时采用基于 GRU 架构的 RNN 网络自回归生成视频,为了避免视频生成时的片段重复现象,提出了“梯度角惩罚”。另外本文展示了效果不太好的“偏移技巧”,即将生成视频的运动转移到不同的主题。
概览

创新
- 在预训练 styleGAN 的 $\mathcal W+$ 空间上对时间序列进行训练以生成 video,模型完全在 $\mathcal W+$ 空间监督
- 提出一种 offset trick,用以将生成的视频运动转化至不同的主题
- 使用 gradient angle penalty 惩罚 RNN,用以避免 RNN 生成视频时可能出现的循环问题
- 该方法可以生成手部视频
网络
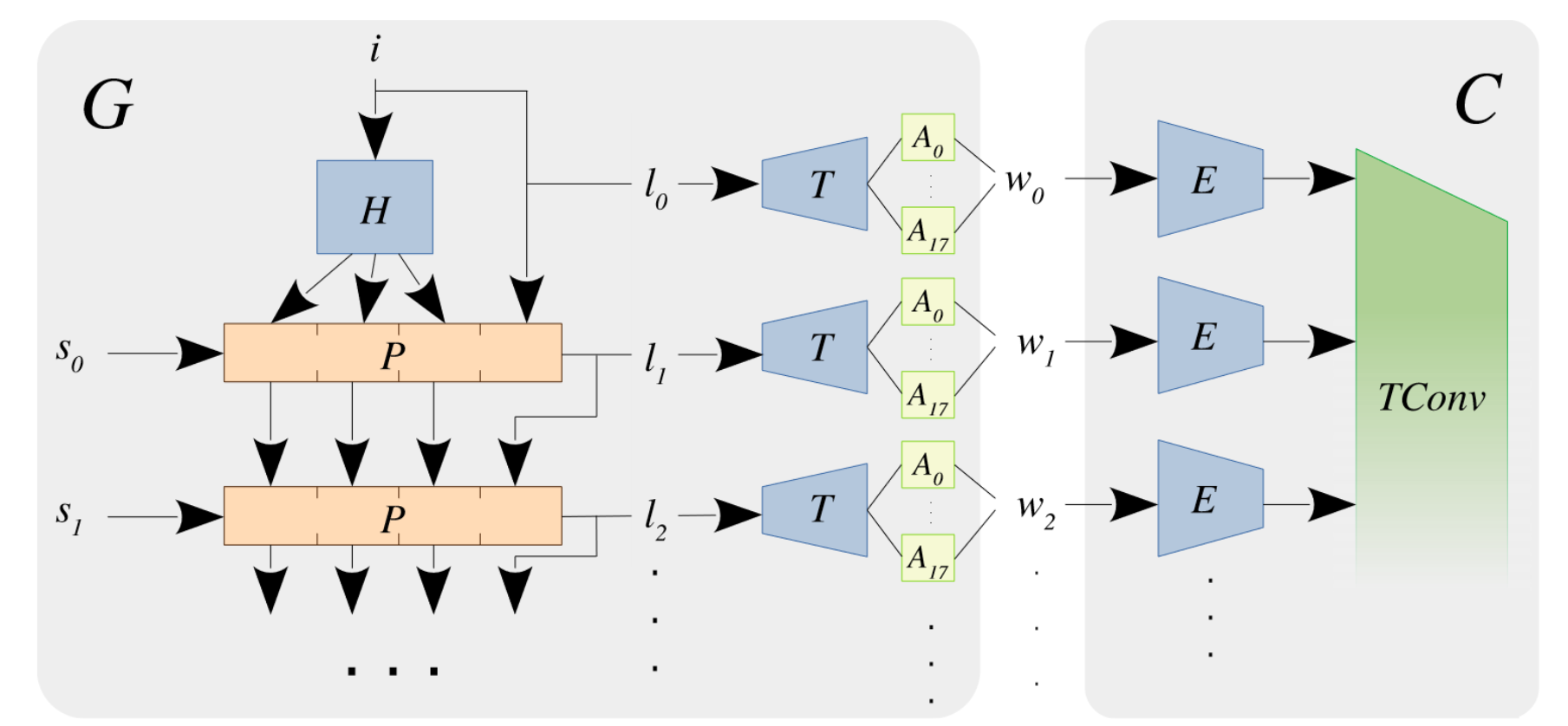
本文的架构是一个 WGAN,具体来说,输入为 $(i,s)$,其中 $i\sim \mathcal N(0,1)^{32},\ s\sim \mathcal N(0,1)^{32\times(t-1)}$,也就是说,$i$ 就代表视频的第一帧,其余的 $s$ 都代表剩余帧。这些初始输入通过一系列 RNN 得到 $l$(这里的 $l$ 对标 styleGAN 中的 $z$),然后经过 $T$ 的特征映射(对标 styleGAN 的 $F$)并进一步学习仿射变换得到 $\mathcal W+$ 空间的各个帧的隐向量 $w$(这里的 $w$ 对标到 pSp 之中是 $18\times 512$ 的向量,包含一帧的所有粒度特征控制)。之后的 $C$ 即判别器,只是换了一个名字,之所以判别器需要包括 $E,\ TConv$ 两个部分,主要考虑到生成器与判别器的网络容量大小关系。
整体来说,本文的前向流程如下:
- 对于初始视频 $V$ 其中包含 $t$ 帧 $I_t$,首先将每一帧通过预训练的 pSp 映射至 $w_k^+\in\mathcal W+ ,\ k\in[0,t)$
- 接着从 $\mathcal N(0,1)$ 中采样 $i$ 和 $t-1$ 个 $s$,输入生成器 $G$,$G(i,s)=\{l_k\},k\in[0,t)$
- 将得到的 $t$ 个 $l$ 分别通过映射 $T$ 和 18 个仿射映射,得到 $w_k\in\mathcal W+,\ l\in[0,t)$
- 对于 $w_k,\ w_k^+$,将其分别作为 fake 和 real 输入判别器 $C$,通过对抗训练得到合适的 $G$
⛔本文的架构理论上可以生成任意长度的视频(测试时),训练为了考虑判别器还是只能产生 25 帧
$G$ 的网络结构
生成器包含一个 $H$ 以及一个由 4 个GRU单元组成的 $P$,$P$ 处理“每时间步随机”,目的是产生多样的运动方式。为了初始化 GRU 内存,让 MLP $H$ 伪生成前三个单元的一些内存内容,而最后一个单元则用 $i$ 初始化。使用数学语言描述为:
简单来说,第 $k$ 层 $P_k$ 接收输入 $s_k$,和上一层传下来的四个隐特征 $\{h_{k-1,0\to3}\}$, 输出下一层 $P_{k+1}$ 所需要的隐特征,同时每一层输出的隐特征的最后一个直接当做输出。
损失函数(“梯度角惩罚”)(gradient angle penalty)
本文的损失描述为:
其中前两项记为 WGAN 的损失函数描述,最后一项即本文新提出的梯度角惩罚,其目的是防止使用 RNN 架构生成长视频时出现“循环视频片段”的情况。
其具体的做法为:
- 计算最后一帧相对于第一帧的偏移 $d,\ d=norm(l_{t-1}-l_0)$
- 计算 $d$ 对每一个 $s$ 的梯度($t-1$ 个 ),对其计算二阶范数(一阶应该也行),作为分子
- 计算 $d$ 对 $i$ 的梯度,作为分母
- 取 arctan,得到角度 $\phi$,最终的 $\mathcal L_{GAP}=max(0, \frac\pi 4-\phi)^2$
即:
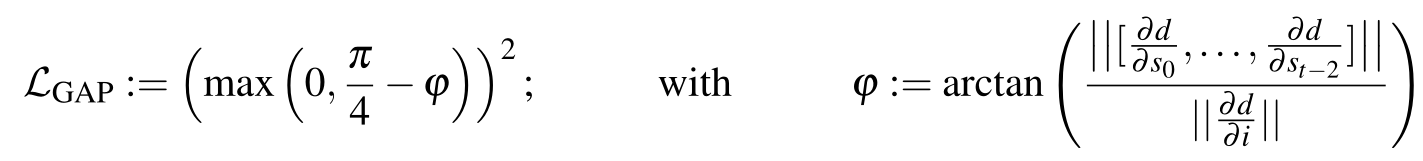
这个式子的有效性原理在于:假如视频的生成出现了循环,那么就说明生成的 video 没有太和随机采样的 $s$ 有关,即更多地和 $i$ 有关,此时关于 $i$ 的梯度会明显大于关于其他采样的 $s$ 的梯度,这时候 $\phi$ 就会接近 0,返回的 loss 也就会变大。
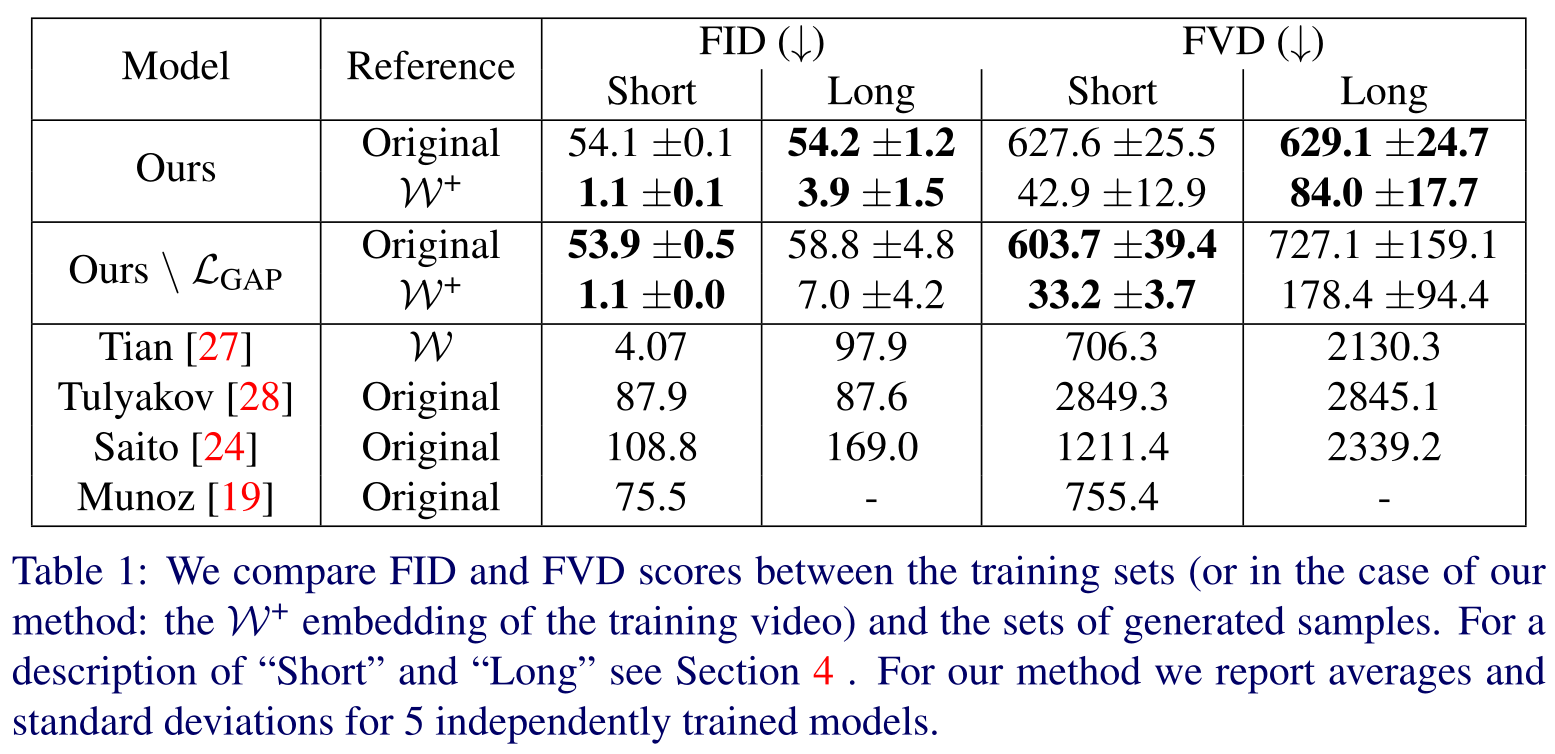
结果
在短视频和长视频上的 FID 和 FVD 的值,先 mark 一下,到时候可能要和他比一比
生成的视频质量,还是很棒的(毕竟基于 pSp,至少放一些直接 reverse 的结果也不会差)

偏移技巧:将生成的视频转化为不同的主题(也就是视频驱动人脸生成视频),效果满差的感觉,下图中上面是生成的正常视频,下面的左一,左二是普通的方法,左三,左四是他提出的基于 PCA 的正交迁移方法,因为效果属实不好,需要的话后期再看

本文还专门强调自己虽然是专注于人脸视频生成,但是所设计的方法之中没有针对人脸设计的模块,因此也放了一些其他 domain 的结果,可以看出确实多了些多样性出来
