attention is all you need【机器翻译】【NIPS】
摘要
原始transformer,RNN(解决 序列建模/位置敏感)$\to$ LSTM(解决 参数依赖/难以训练)$\to$transformer(解决 并行运算)。此篇笔记简要介绍网络、详细分析过程
概览
原始transformer,RNN(解决 序列建模/位置敏感)$\to$ LSTM(解决 参数依赖/难以训练)$\to$transformer(解决 并行运算)。此篇笔记简要介绍网络、详细分析过程
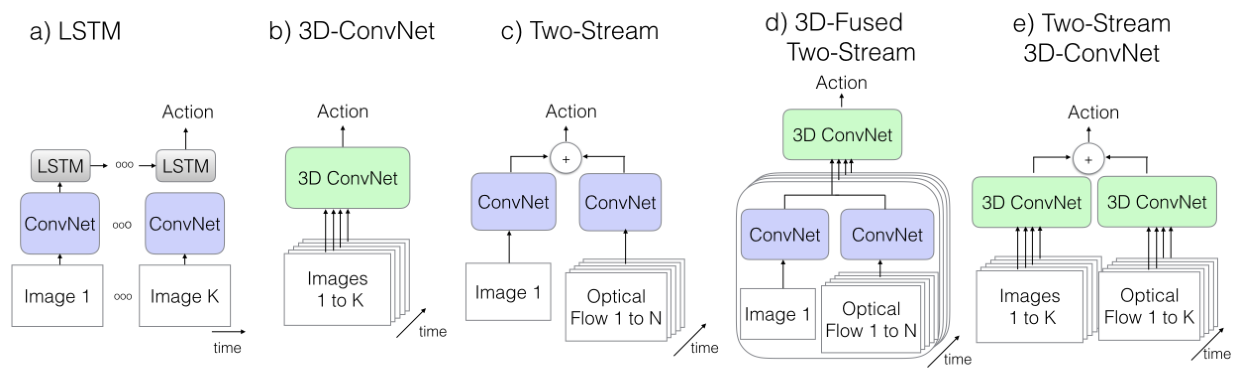
本文提出了一种新的视频理解网络结构,和一个新的数据集。这两个都是里程碑式的工作,对于新网络架构,其名字叫做“膨胀的3D网络”,方法简单有效,仅是将 2D 卷积核进行 3D 膨胀,相对于以往的训练 3D 卷积核,关键就在于先训练 2D 网络,再在不改变权重的情况下进行扩张后进行微调。新的数据集也十分有效,大小适合,范围多样,是视频理解领域新工作绕不开的测试数据集。

该论文完成了光场数据的压缩表示,使用自编码器的方法将光场数据压缩为一个深度图和一个中央视觉图,并且支持编辑之后的中央视觉图和原深度图进行光场重建。

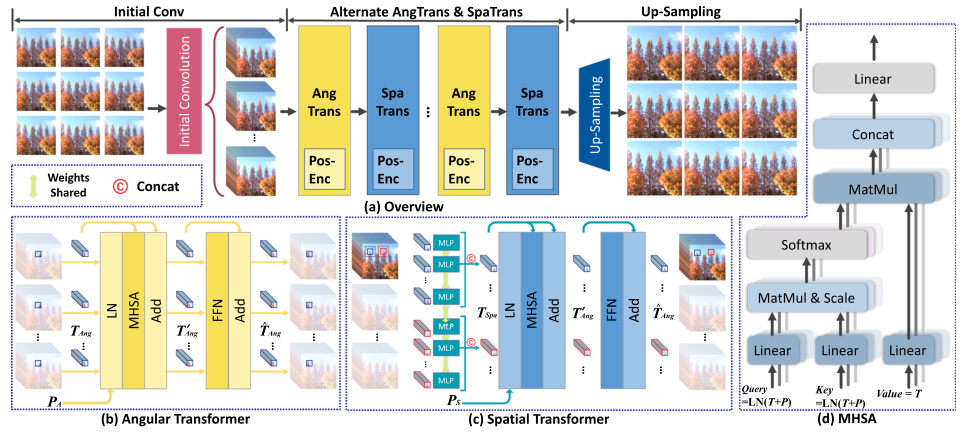
本文将transformer方法应用到了光场超分的领域,提出了一个简单且有效的baseline,相对于SOTA具有更小的计算代价和更优的效果。具体来说,提出了角度转换和空间转换两个模块,意图更好地学习不同视图之间的互补性。
本文是为了完成毕业论文进行的文献收集和阅读,在此对各个具备较高参考性的文章进行总结提炼,本文最主要参考的文章进行了精读,链接见此。初步的设想下,本文的自编码器分为编码器和解码器两个子网络,编码器把一个光场输入编码为一个RGB图像,光场的结构性信息理论上被隐式地编码到RGB图像之中。而解码器则利用这个图像进行光场重建。
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
说明:你不能倾斜容器。