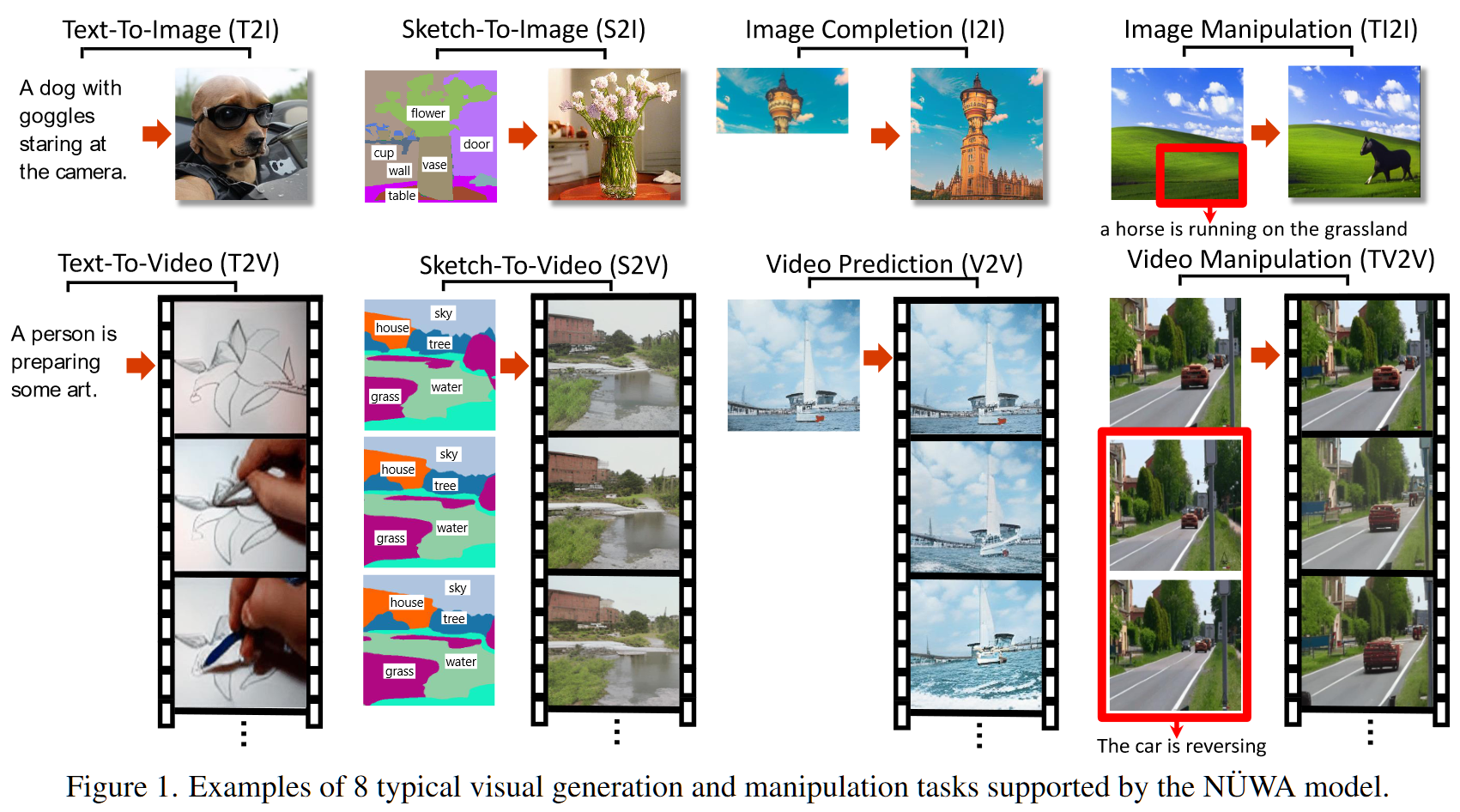
diffusion theories
摘要
本文将承接上文的 DDPM,继续介绍其他的扩散模型理论,以及对扩散模型扩展的探索:
- SMLD(NIPS2019):Generative modeling by estimating gradients of the data distribution
- SDE(ICLR2021):Score-Based Generative Modeling through Stochastic Differential Equations