transformer_implements
摘要
在 视频行为识别 / 视频实例分割 / 视频超分辨率 等领域具备一定效果的 transformer backbone
概览
- TeViT
- UniFormer
TeViT : Temporally Efficient Vision Transformer for Video Instance Segmentation
CVPR2022Oral 视频语义分割 paper code
特点
- 一种信使 token+移位的时间维度特征融合方法
- 多尺度的金字塔结构,生成多个不同尺度的特征图用于下一步分割头
网络
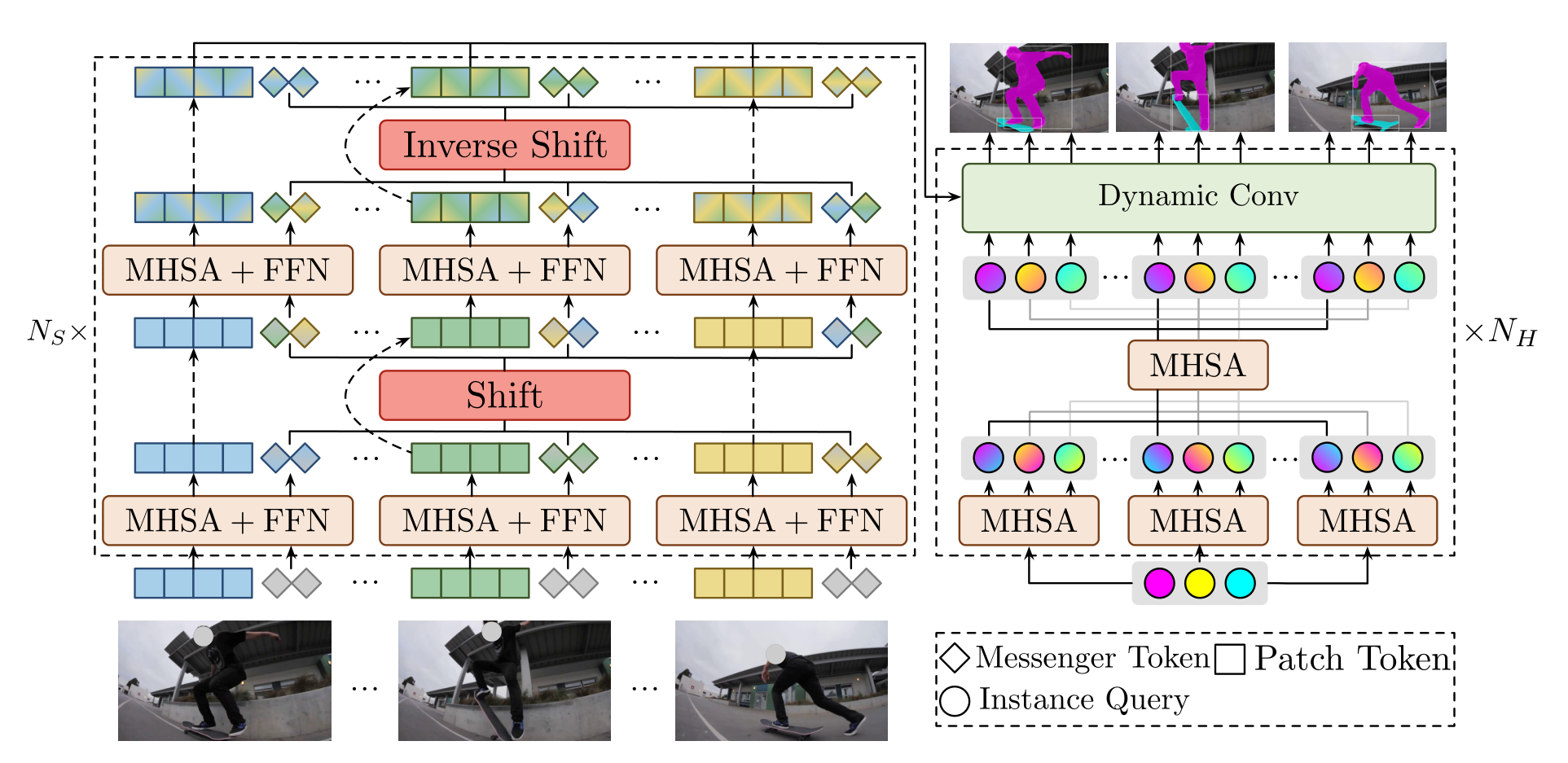
对于基于 transformer 的特征提取 backbone,串行地打四个不同 size 的 patch,将得到的 token 经过 embeding 输入网络,从而生成 4 个比原图像降采样 4,8,16,32 的特征图序列 $\{F_i^1,F_i^2,F_i^3,F_i^4\}_{i=1}^T$,每个 $F$ 都表示了 T 帧中不同感受野的特征,用于下一步的分类/回归任务。
对于每个尺度下的 backbone,其具体操作如下:
- 对一个 T 帧的 token $x_i\to(\frac{HW}{P^2},C)$,配备 M 个信使 token $m_i\to(M,C)$,两者 concat 之后为 $\{x_i,m_i\}_{i=1}^T\to(T,\frac{HW}{P^2}+M,C)$
- 对于配备好信使 token 的新数据,在经过 backbone 的时候,每两个 MHSA+FFN 为一次循环,对每一次循环的操作如下:
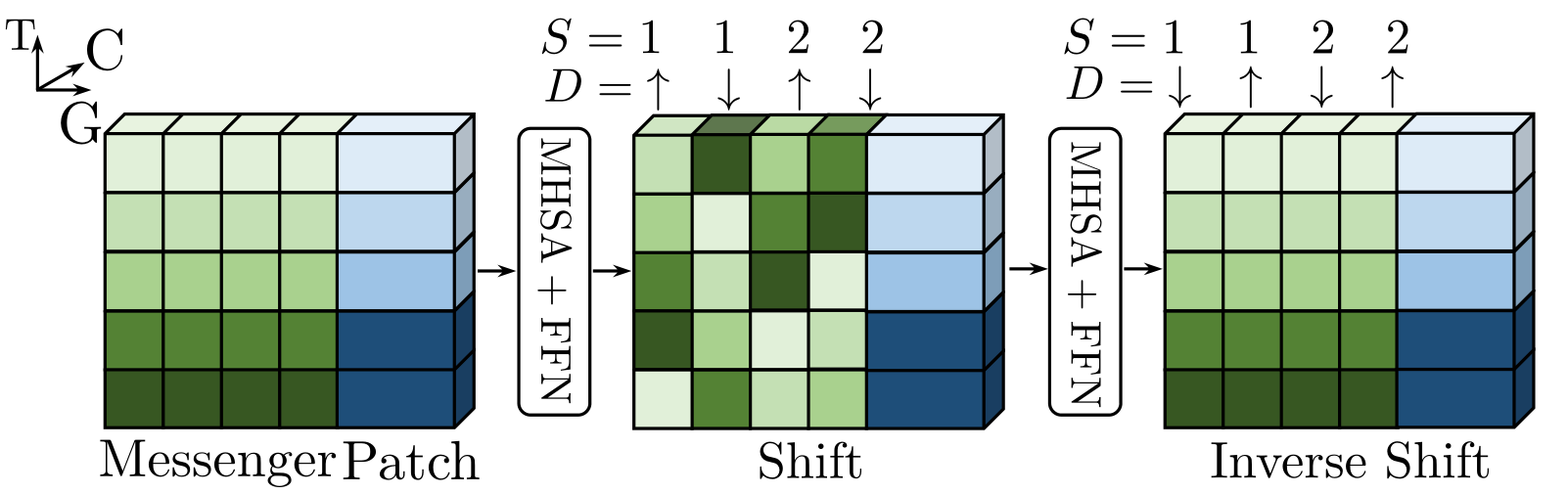
- 图中绿色部分代表信使 token,蓝色部分代表原始的 token,上下维度表示时间维度(图中显示为 5 帧),左右维度表示信使分组个数(图中显示为 4 组,注意,每组不见得只有一个信使 token),前后维度表示 channel
- 在每轮循环中,第一个 MHSA+FFN 直接在 $\{x_i,m_i\}_{i=1}^T$ 上进行,目的是使所有的 $m$ 都学到自己对应原始 token 的信息
- 接着进行 shift,位移的是信使 token,按组进行 shift,具体方式为逐组地上下位移,位移步长为 1122···
- 再进行第二个 MHSA+FFN,和上一步一样的目的,交换不同帧序列的信息 token,以交换帧间信息
- 接着进行反向 shift,即将之前 shift 的内容再换回去,该设计旨在随着网络的深入保持稳定的时间接受场
- 将此时输出的原始 token 记为特征序列 $\{F_i\}\to(T,\frac{HW}{P^2},C)$,此时得到的特征还原至 $(T,C,\frac H P,\frac WP)$ 接着打 patch,得到更小尺度的特征,如此循环四次,最终得到 4,8,16,32 的降采样序列(即 patch size 分别取 4,2,2,2)
- 遵循 PVT,将四个特征序列 $\{F_i^{1,2,3,4}\}^T$ 输入 STQI(时空查询交互头,即上图的右半部分)这部分是任务导向的。
UniFormer : Unified Transformer for Efficient Spatiotemporal Representation Learning
特点
- 提出一种基于关系聚合器的注意力结构,在形式上统一了 Conv 和 transformer,在取得大部分 transformer 架构结果的基础上加了 efficient
- 通过 4 stage 的设置使其具备了多尺度信息
网络
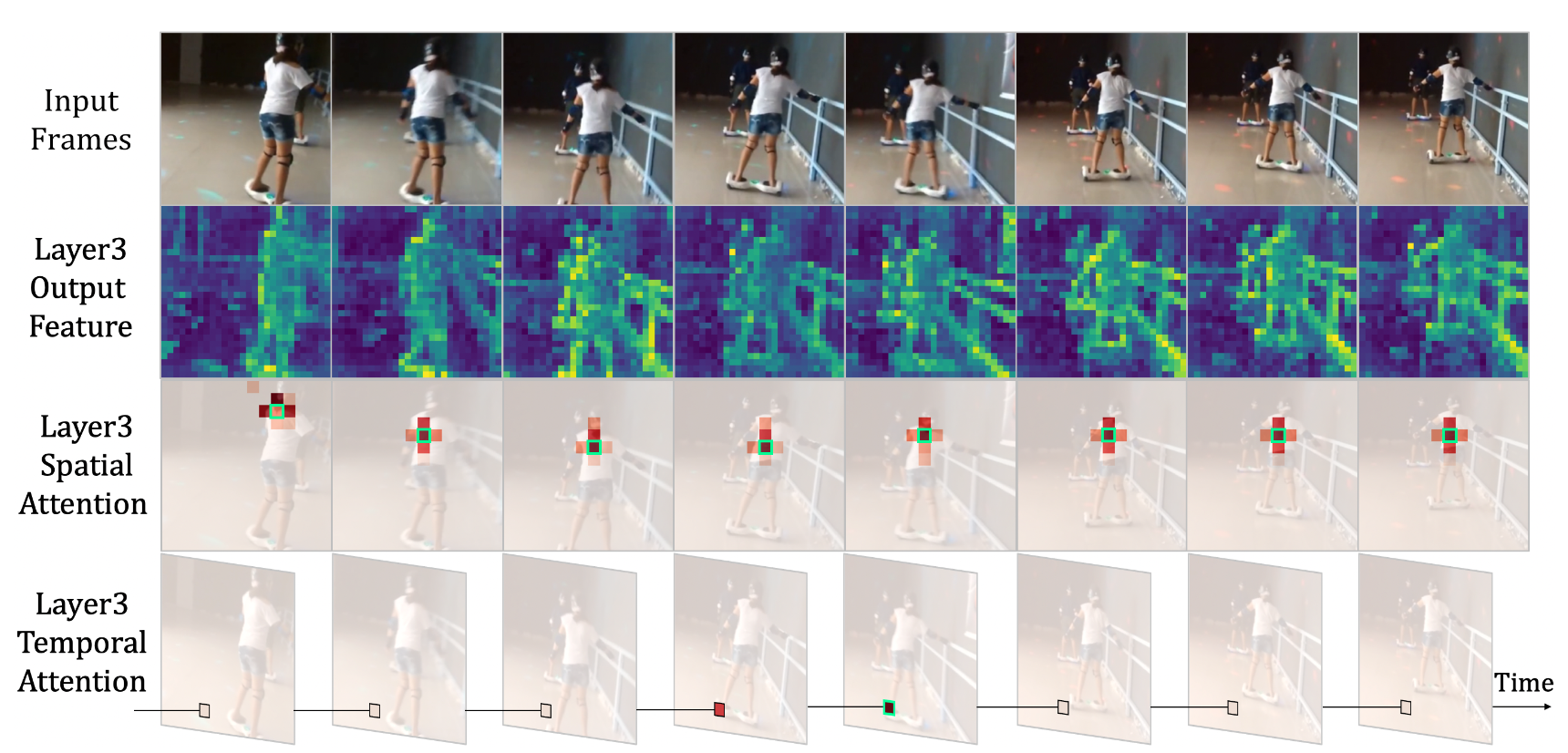
具体来说,本文首先分析了 timesformer 在行为识别上的表现,展示了训练好的 timesformer 在第三层的输出,包括时间注意力和空间注意力,可以发现的结论是:对于第三层的输出,某个 patch 在时间上只对上下帧具备 att,在空间上只对临近位置有 att,从而得出一个结论:前期的浅层网络应当关注局部信息,而后期深层网络关注全局信息,使用纯 transformer 架构相当于前期用了较大的计算资源做了 Conv 的事情,故而应当对 transformer 的 att 计算方式进行额外的设计。
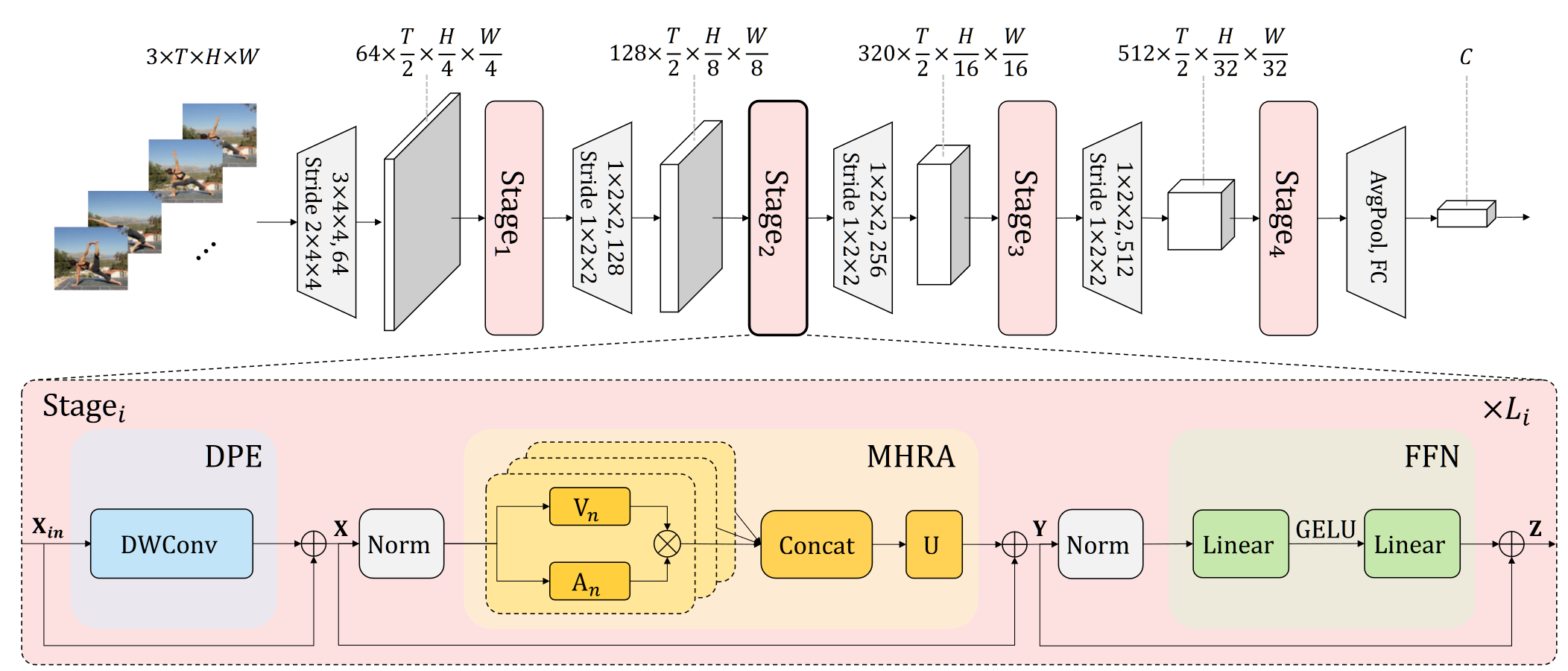
因此本文设计了一种“统一化”的 transformer 注意力计算,其实大概就是用一种描述统一地描述了 conv 和标准 transformer,至于 DPE 和 FFN,实际上创新性不大,或许用处是有的。具体来说,在 4 个 stage 中,前两个做局部 transformer,后两个做全局 transformer。
- 对于每一个 stage,输入的 $X_{in}$ 首先经过 PE 打 patch,目的是降采样,此时使用 DWConv,目的是尽可能减少计算量
- 从上计算出 $X$,$X=DPE(X_{in})+X_{in}$
- 将 $X$ 输入 MHRA(多头关系聚合器),具体来说,首先将 $X$ reshape 成 $(L=T\times H\times W,C)$,又分为 $N$ 个头,然后首先通过一个linear 进行等维度的映射,得到 $V_n(X)\to(L,\frac C N)$,目的是聚合上下文信息,同时这个值就可以看做 transformer 中的 $V$
- 接着需要将 $A_n$ 和 $V_n$ 做乘法,作为第 $n$ 个头的输出结果,$A_n$ 的计算方式与 global 或者 local 有关:
- 对于 local,$A_n(X_i,X_j)=a_n^{i-j},\ j\in\Omega^{t\times h\times w}$,含义为在一个小的邻域范围 $\Omega$ 内对两个 token 之间的 att 矩阵计算为一个常数,这个常数基于学习得到,基本上实现了类似 Conv 的信息聚合方式
- 对于 global,$A_n(X_i,X_j)=\frac{e^{Q_n(X_i)K_n(X_j)^T}}{\Sigma_{j’\in\Omega_{T\times H\times W}}e^{Q_n(X_i)K_n(X_j)^T}}$,含义为在全部 token 范围内对两个 token 之间的 att 矩阵表示为 Q 与 K 之间的 $QK^T$ 与 Q 和所有 K 之间的 $\sum QK^T$ 比值,在计算复杂度上,事实上对于原本的 transformer,也需要计算任意 $i,j$ 之间的 $Q^TK$ 结果
- 无论是对 local 还是 global,$A_n$ 都表示注意力矩阵 $QK^T$,只不过将 Conv 的计算逻辑使用注意力矩阵的方式重新表述了
- 对于多头的结果,$A_nV_n$ 其实就是 $QK^TV$,从代码来看,softmax 和 scale 一个不少,上述 global 的公式表述也有问题,其实就是标准 att 计算过程,将多头的结果 Concat,之后和 U 相乘,也是 transformer 的标准操作
- 输出的结果 $Y$ 记为 $Y=MHRA(Norm(X))+X$,并输入 FFN,FFN 如上图,很好理解
由此得到的四个特征图用于下游任务,值得一提的是 efficient 的结果,看上去相对于 timesformer 取得基本一致的 acc 的时候算力小很多。
