AN IMAGE IS WORTH 16X16 WORDS 【图像分类】 ICLR
摘要
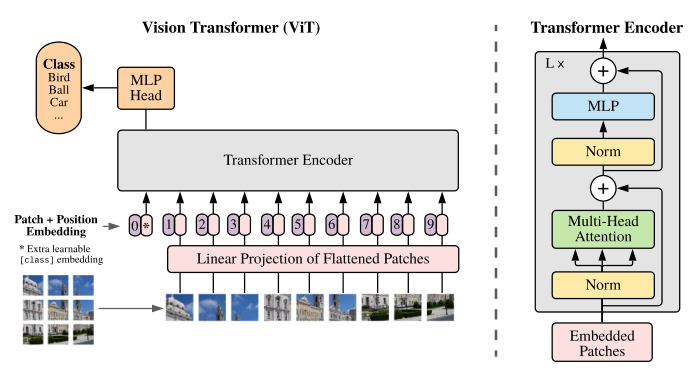
VIT(vision transformer) 是第一个将NLP领域的颠覆性成果——transformer成功迁移到视觉领域的工作。VIT采用了非常简单的操作使图像可以像文字序列一样输入transformer架构之中。正如题目所说,VIT将图像分为许多16x16的patch,并将这些patch视为句子中的word,将图像视为句子,几乎完全使用transformer架构完成了对CNN的超越。
概览
创新
- 将图像打成patch,几乎使用标准transformer进行处理
- 借鉴bert,采用cls作为标志位进行分类
理论
整体来说,该工作与普通的transformer差别不大,基本过程几乎没有差别,在这里的分析过程中不讲理由,只按照论文的前向过程走一遍,看一下VIT中的各个参数维度变化。
patch embedding
初始输入的图像 image 具有 $H\times W\times C$ 的 shape,首先我们需要对每个 image 按照 $P\times P$ 切分成多个 patch,理论上共有 $N = \frac{HW}{P^2}$ 个patch。以 VIT-base 为例,$H = W = 256, P = 32$, 切分之后有8*8=64个patch, 每个patch经过拉平之后大小为32*32=1024维,此时输入序列为 $(N, P^2\times C)$,在这之后,为了对准标准 transformer,使用一个Linear层完成从 $P^2\times C \rightarrow D$ 的维度转化。因此输入的序列维度为 $(N,D)$。VIT-base 中 $D=1024$。
1 | assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.' # 保证一定能够完整切块 |
position embedding
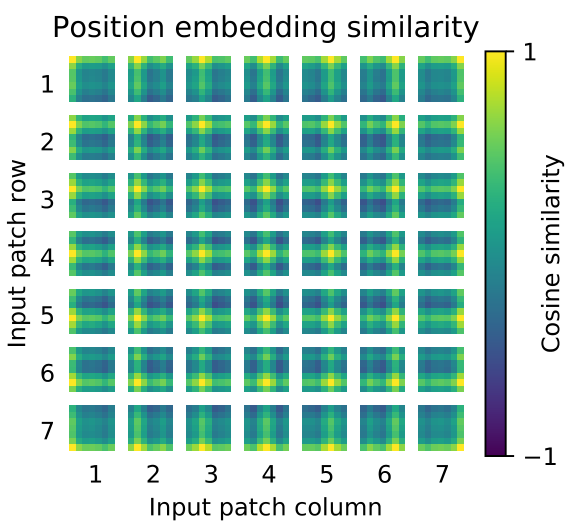
VIT的位置编码不像普通transformer的编码直接指定,而是通过学习进行编码,VIT将会初始化一个size和输入序列一致的位置编码 $(N,D)$,然后和序列每个位置的编码直接相加,通过梯度下降学习。事实上,通过这种策略学习到的编码在变回2D之后,其大小分布基本表示了每个patch在原图像中的位置,如下图。
在加入位置编码的同时,VIT为了实现分类任务进行了对bert的借鉴,也就是在整个序列的首位加入了一个CLS标志位,直接使用CLS标志位的输出过一个MLP后进行图像分类。
1 | self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) # 位置编码,获取一组正态分布的数据用于训练 |
transformer encoder
这里的计算过程基本和transformer没有区别,详见标准transformer,这里主要说一些不同点,在VIT中,首先要进行LayerNorm再进行MHA,虽然事实上transformer在pytorch中的接口中也提供了这种先做norm的选项。这里没有 $A\&N$ 部分,非要说的话可以说成 $N\&A$,具体地,这 $L$ 次encoder中的变化过程大致是:
这里的 MLP 约等于标准 transformer 中的 FFN,都属于先放大再缩小的全连接层,VIT-base 中的隐藏层维度为 2048,具体到 transformer 中的内部参数,$W_{Q/K/V}\rightarrow (1024,64), headers=6$。另有一处区别于标准transformer,在 MLP 中,其过程中的 RELU 被替换成了 GELU,并且在多处加入了dropout,由于实在有很多地方都加入了dropout,具体哪些位置这里不做记录。
1 | class PreNorm(nn.Module): |
MLP header
最后的MLP就是一个普通的MLP,$\rm layernorm +Linear$就无了。
1 | self.mlp_head = nn.Sequential( |
损失
由于是分类问题,VIT使用最终输出的结果和真实label进行计算交叉熵损失。其SOTA的性能由JFT的大规模数据集预训练保证。