Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
【长视频生成】【ECCV2022】【paper】【code】
摘要
本文提出了一种遵循 VQGAN+transformer 架构的长视频生成方法,通过对以往的方法在自回归生成长视频的探索,本文提出了两个见解:1.3D-VQGAN 在自编码时为了获得对应 shape 而进行的时间维度上的 zero padding 是长视频生成崩溃的原因,2.在一定的范围内(如生成 1k 帧),直接用自回归进行视频生成会产生很长的时间注意力(因为计算了 $p(z_{1000}|z_{1:999})$),这也可能是导致崩溃的原因。据此本文提出了一些改动,形成了对时间不敏感(Time-Agnostic)的 VQGAN,和对时间敏感 (Time-Sensitive)的 transformer。
概览

创新
- 发现 VQGAN 在时间维度上的 zero padding 是长视频生成的崩溃原因,使用复制进行 padding
- 提出了一种分层预测的 transformer,首先预测关键帧,再根据关键帧进行插值预测
网络
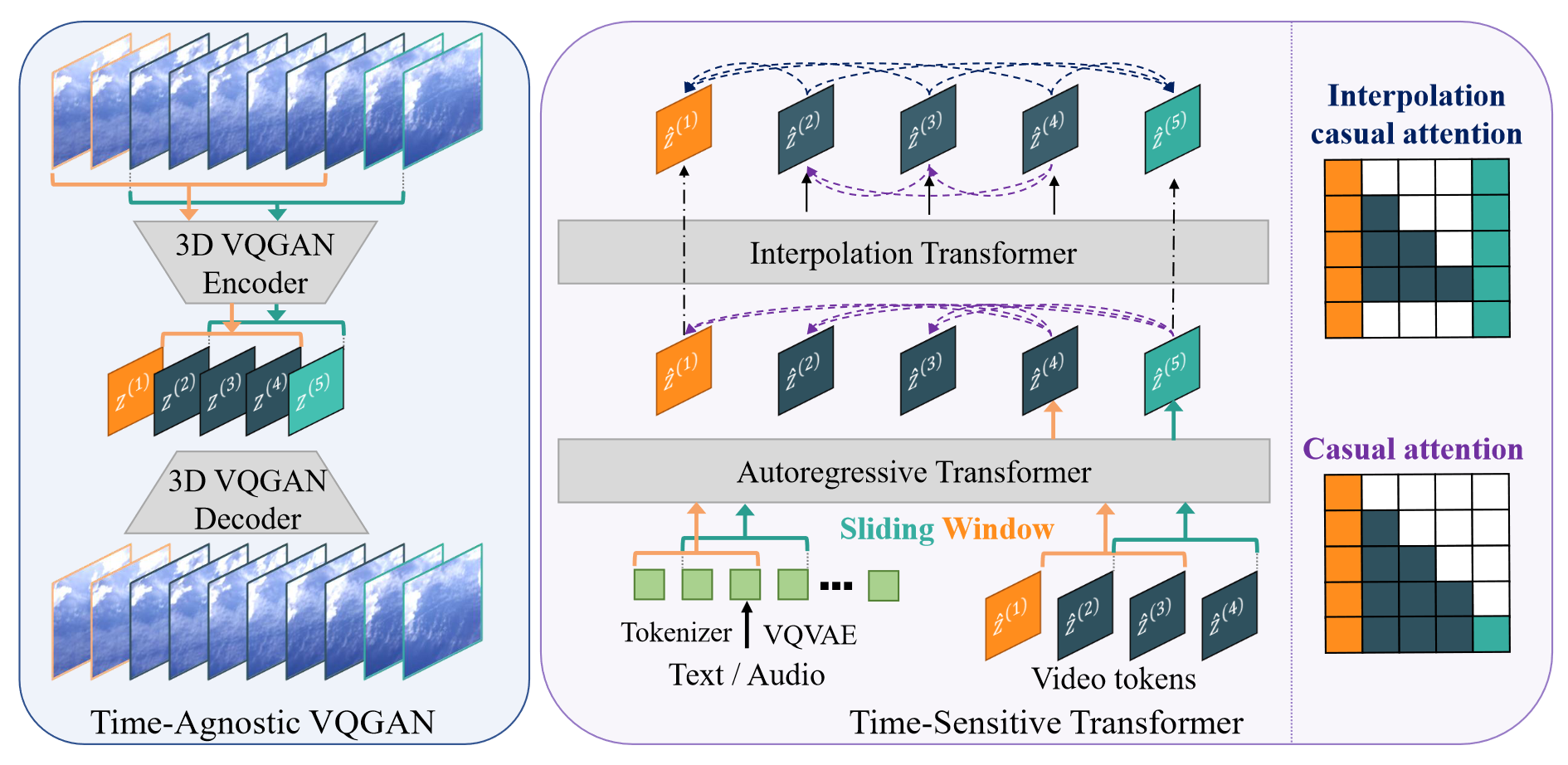
本文的网络结构包含两个方面,一是可以在固定窗口大小下进行视频自编码的 3D-VQGAN,然后是基于 VQVAE 采样的文本或音频(也可以是条件视频生成的条件)进行引导生成。
对于 3D-VQGAN,其网络的设计简单地将标准 VQGAN 的 2D 卷积进行 3D 替换。但是在 padding 时采用复制的方法进行,具体来说在时间维度的 padding 可以从以下三个角度考虑,并且最终选定复制填充:
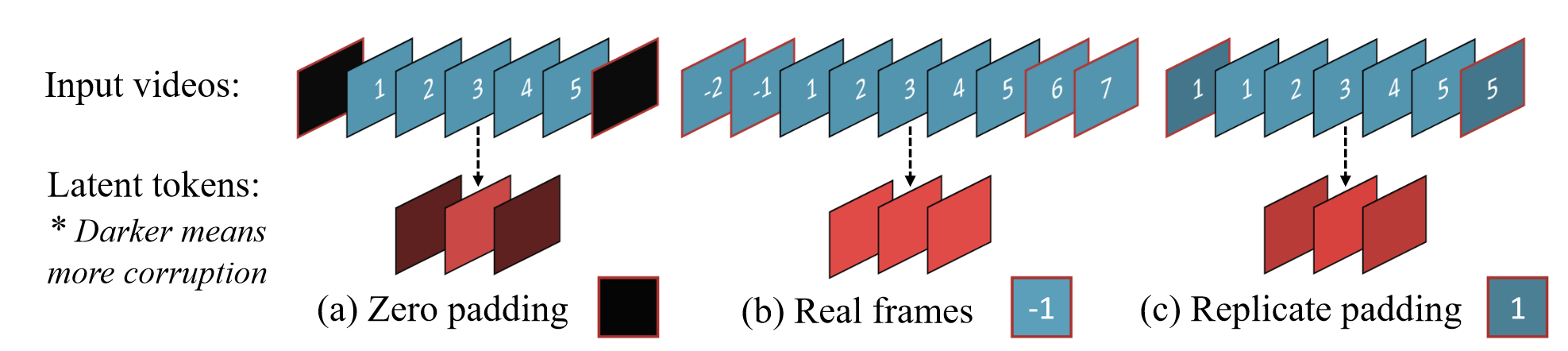
- zero padding,在时间卷积时使用 0 填充帧以获得对应的 shape,这样会导致长视频崩溃
- 使用真实帧填充,$(b)$ 中的 -1,-2 即倒数第 1,2 帧,也就是将视频看做循环播放,这样可以解决崩溃问题,但是在降采样率很大的时候会出现较大的复杂度
- 使用复制帧填充,即将视频开始帧之前和结束帧之后当成视频被“冻结”了,实现简单,并且效果与 $(b)$ 基本一致
- 🔥由于过短的视频可能要进行大量的 padding,因此在训练时将短视频直接剔除
在确定网络结构之后,本文的损失函数创新性属于有但不多,具体来说包括:
- 用于重建的 VQVAE loss:
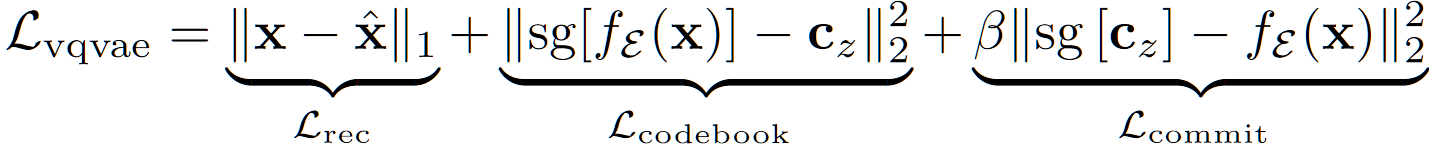
- 在更新 $L_{codebook}$ 时采用 EMA
- 对抗性损失 $L_{disc}$,其描述为:
- 对于空间维度的判别器,度量每一帧的生成质量 $f_{D_s}$,对于时间维度的判别器,度量运动有效性的 $f_{D_t}$,真实 token $x$,生成的伪 token $\hat x$
- $L_{disc}=\log f_{D_{s/t}}(x)+\log (1-f_{D_{s/t}}(\hat x))$
- 特征匹配损失 $L_{match}$,其主要包含感知损失和判别器的每一层加权损失,其描述为:
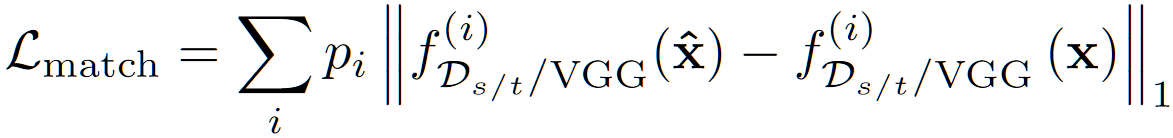
- 其中 $s/t/VGG$ 表示 $VGG$ 时为 L1 感知损失,$s/t$ 时才有对应的 $p_i$,$i$ 表示 $f_{D_{s/t}}$ 的第 $i$ 层的值,也就是参考 VGG 损失写的判别器在每一层的特征匹配,其中 $p_i$ 是常数
- 最终优化目标结合上述三个损失,具体来说:
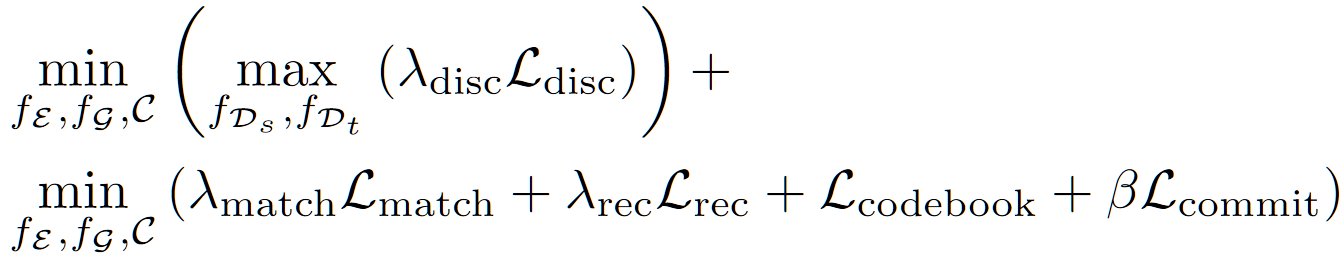
- 其中所有的 $\lambda,\ \beta$ 都是超参数
对于第二阶段的 transformer,其每个 transformer block 包含两个部分:1.自回归生成的下一帧隐编码,2.插帧生成的中间帧隐编码(在没开源的情况下,这种描述是不精确的,具体来说并不确定:1.自回归生成稀疏编码,插帧生成中间编码,这个更合理;2.自回归生成所有编码,插帧细化中间编码,这个更符合网络图)。
对于第一个 block,其作用就是自回归进行下一个的生成,其优化目标为 $E_{z\sim p(z)}[-\log p(z_i|z_{0:i})]$。
对于第二个 block,相对于普通的 casual attn,插帧下的 attn 方式略有不同,本文做了如下三种尝试,最终选择了 $(c)$:
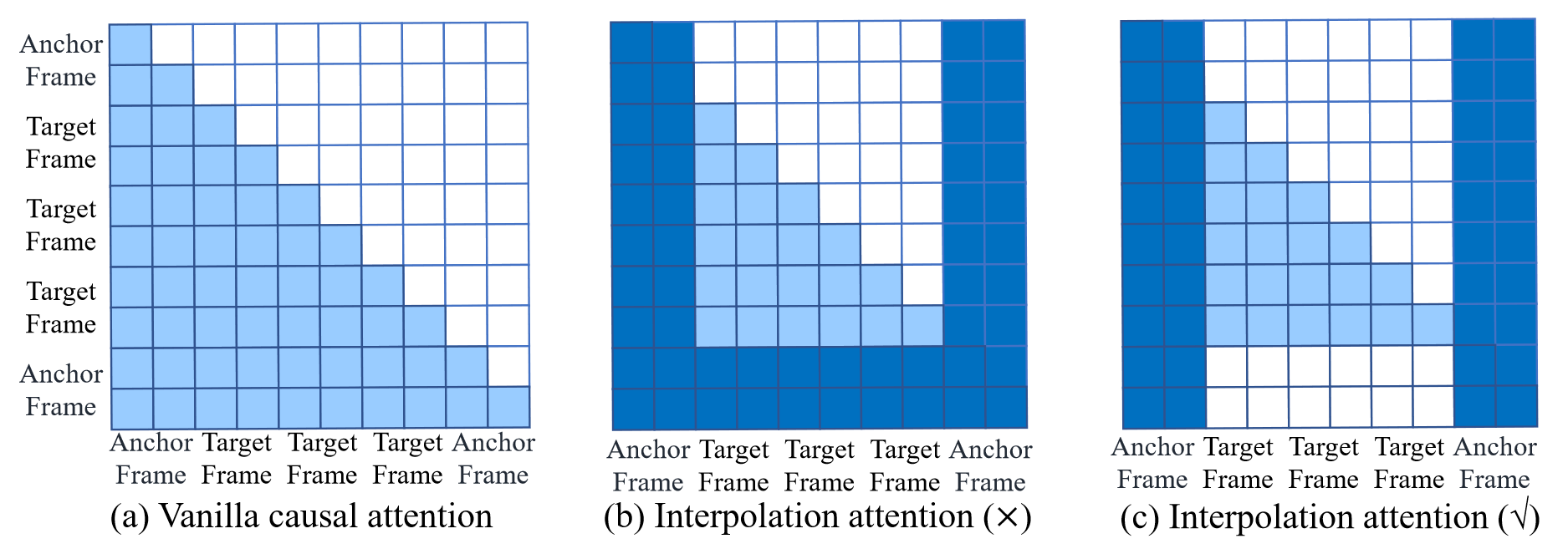
- $(a)$ 是原始的 causal attn,这里的每一帧都能看到前面所有帧的隐编码
- $(b)$ 是一种变体,这里的每一帧可以看到前面所有帧的隐编码,同时包括插帧边界的隐编码,但是边界帧可以看到中间生成了哪些帧(这样会导致中间帧也跟随全部隐编码进行更新,就淡化了 causal
- $(c)$ 是另一种变体,这里的每一帧(非边界)可以看到前面所有帧和边界帧,边界帧只能看到边界帧
通过这种分层设计的模型,本文通过实验验证提升了模型的长期预测能力,能够保持视频从头到尾的一致主题。
结果
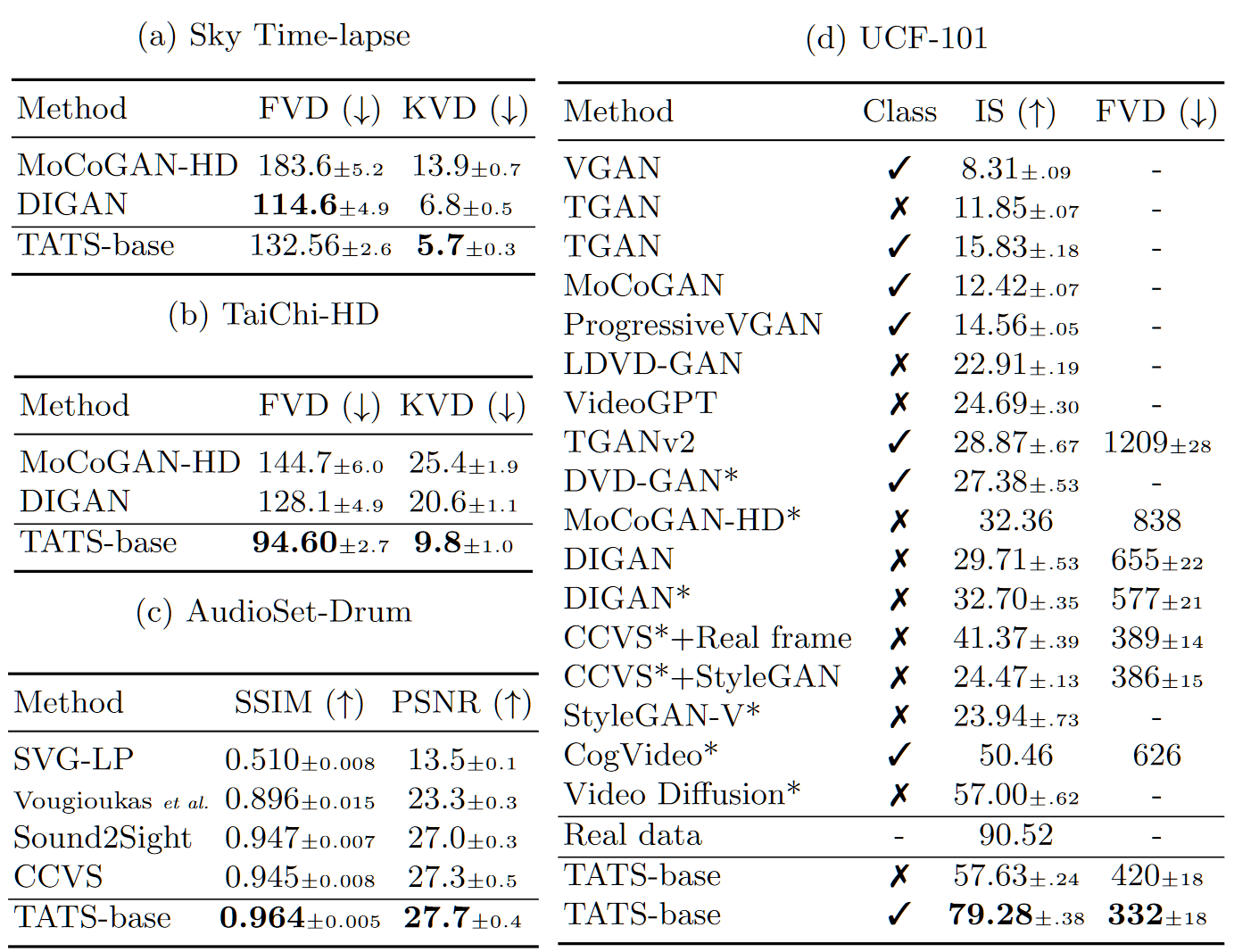
- 在各个数据集上的 FVD,其中 KVD 来自:Towards accurate generative models of video: A new metric & challenges
- 长视频生成,整体来说分辨率并不高,并且伪影也很多,但是可以看出整个视频是符合某一个主题的

更多的结果(包括长视频游戏动画生成)见:https://songweige.github.io/projects/tats/