NUWA: Visual Synthesis Pre-training for Neural visUal World creAtion
【图/视频生成】【ECCV2022】【paper】【code】
摘要
本文提出了一种统一的文本图像视频表示方法,基于此实现了全模态统一的视频/图像条件生成,值得一提的是,在本文之后,MSRA 又推出了能生成 38912 x 2048 分辨率图像的 NUWA-Infinity,以及 23 年 4 月推出了能生成 11 mins 动画的 NUWA-XL。网络使用 VQGAN 的结构,搭建了基于 transformer 的编解码器,为了解决复杂度的问题设计了 3DNA 的近邻结构。
概览
创新
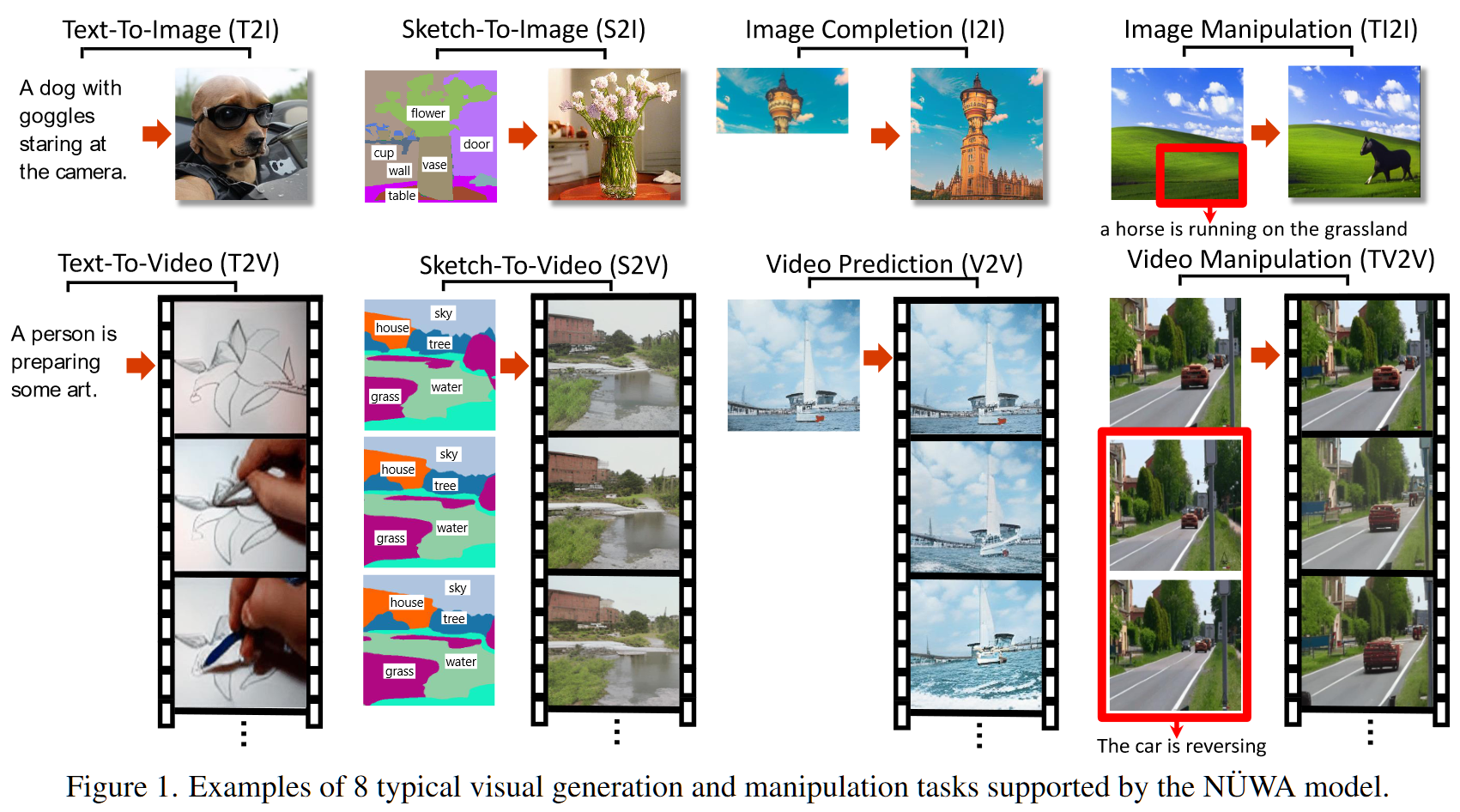
- 一种全统一(文本+图像+视频)的多模态生成模型
- 一种基于近邻的注意力计算方法 3DNA(3D Nearby Attention),有效减少了视频 transformer 复杂度
网络
为了能够将文本和图像视频一起表示,本文采用 $X\in\mathbb R^{h\times w\times s\times d}$ 的方式表示输入,其中 $h,w$ 表示图像的 shape,$s$ 表示文本视频长度,$d$ 表示 token 维度。即文本 $\mathbb R^{1\times 1\times s\times d}$,图像 $\mathbb R^{h\times w\times 1\times d}$,视频 $\mathbb R^{h\times w\times t\times d}$。
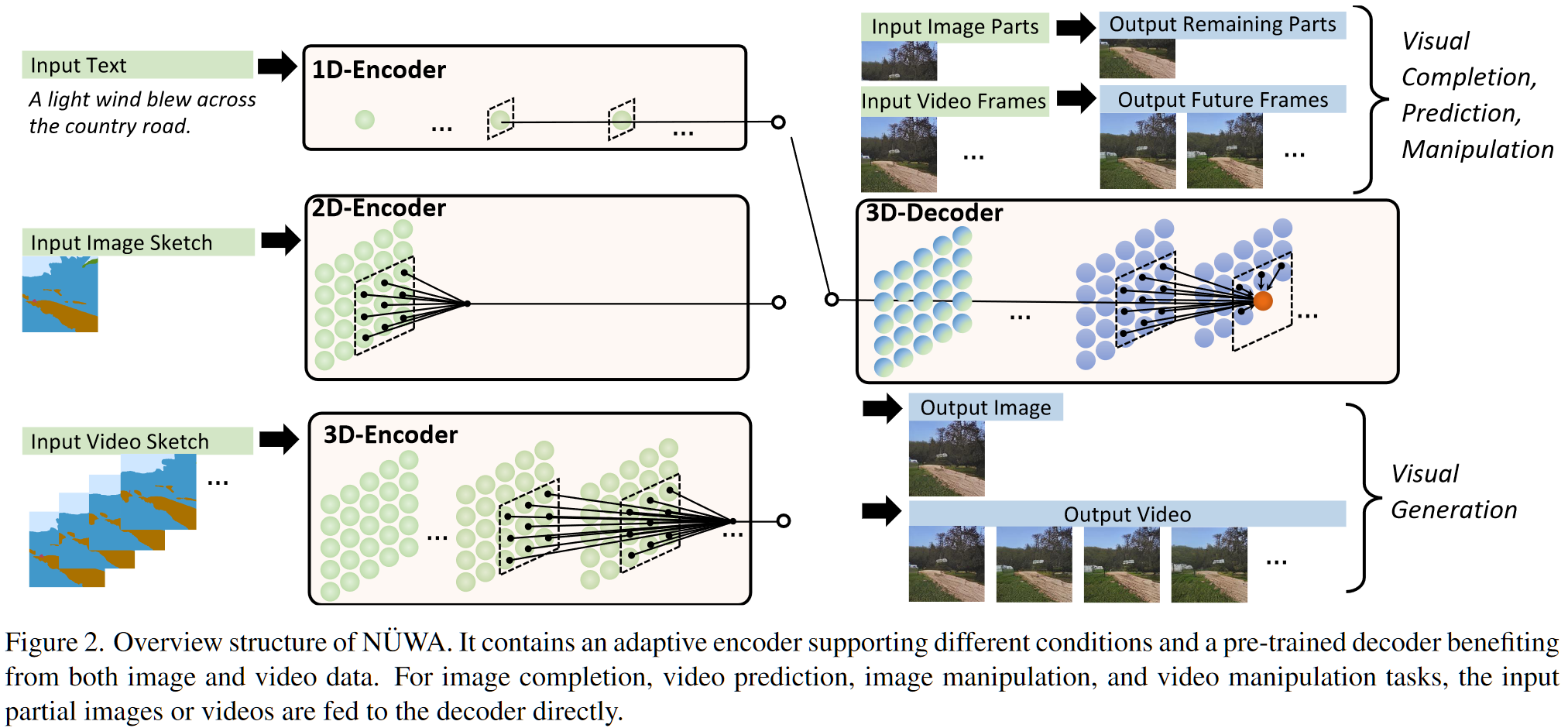
上图中显示的是整体的网络 IO,其中的编解码器结构没有显示,具体在编解码器上的 transformer 结构也没有显示,对于网络结构,具体来说:本文采用基于 transformer 的 VQGAN 架构,对于视频数据的 transformer 结构,为了降低复杂度设计了 3DNA,其做法如下:
- 3DNA 的 IO 表达式为:$Y=3DNA(X,C;W)$,其中 $Y$ 为输出,$X$ 为输入,$C$ 为条件,$W$ 为参数
- 其中输入的 shape 为:$X\in\mathbb R^{h\times w\times s\times d_{in}},\ C\in\mathbb R^{h’\times w’\times s’\times d_{in}}$,都打过 patch 了
- 对于 $X$ 的下标 $(i,j,k)$,首先寻找 $C$ 中对应的下标 $(i’,j’,k’)=([i\frac {h’}h],[j\frac {w’}w],[k\frac {s’}s])$
- 寻找 $C$ 中和 $(i’,j’,k’)$ 临近的 patch idx $N\to(e^h,e^w,e^s,d_{in})$,仅对这些做 attn,其中 $e^h,e^w,e^s$ 在图像下为 3,3,1,在视频下为 3,3,3
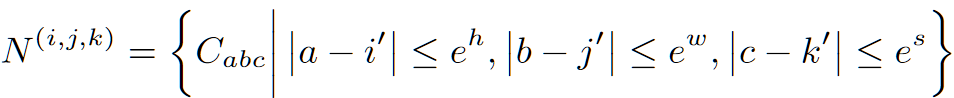
- 接下来计算 attn ,对于 $Y$ 的 $(i,j,k)$ 下标,结果为:$Y_{(i,j,k)}=softmax(\frac{QK^T}{d_{in}})V\to(h,w,s,d_{out})$,再通过 MLP 即可。其中
- $Q=X\times W^Q\to(h,w,s,d_{out})$
- $K=N\times W^K\to(e^h,e^w,e^s,d_{out})$
- $V=N\times W^V\to(e^h,e^w,e^s,d_{out})$
- 该 attn 计算需要经过共 $l$ 层,对 $C$ 来说也需要同步逐层更新:$C^l=3DNA(C^{l-1}, C^{l-1})$
- 在计算 attn 的过程中的位置编码为可学习的相对位置编码,在 $h,w,s$ 三个维度分开学习
- 使用 441x256 的codebook dim,codebook size 为 12288,进行 VQ
- 使用完全反向的解码器进行解码,loss 采用 VQGAN 的loss
- 对于第二阶段,由于本文做了视频文本图像三个任务(文本到图像,视频预测和文本到视频),因此第二阶段采用 GPT 类型的三个损失函数
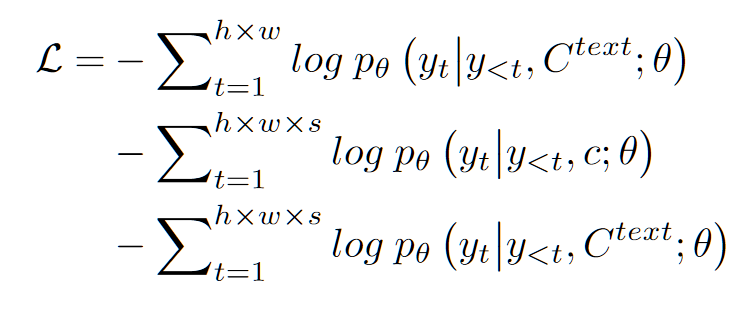
结果
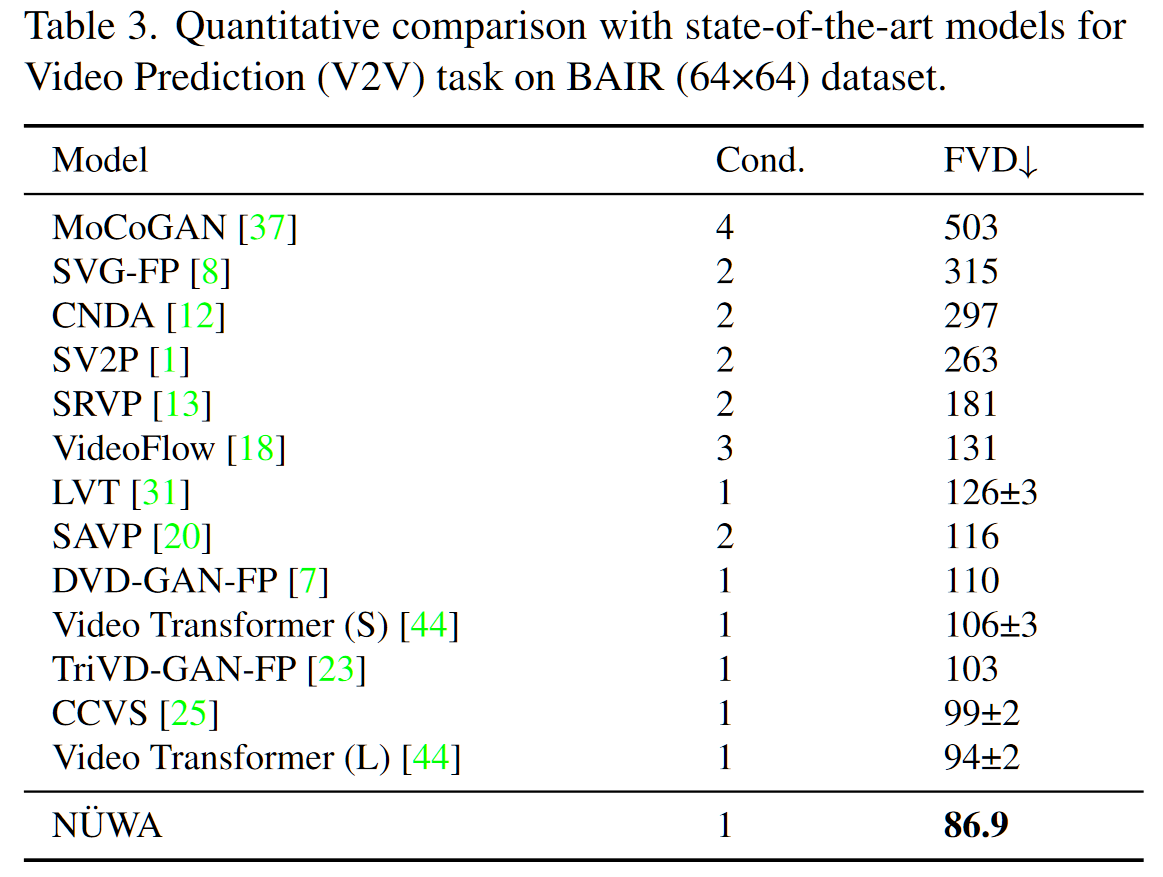
本文的实验十分翔实充分,在补充材料里给了将近 20 页的各种实验,无论是不同任务上的结果还是消融实验都很多,这里只列一下主任务结果和视频预测 FVD。
- 和其他模型在文转图的视觉结果对比

- 和其他模型在文转视频视觉效果对比

- 视频预测结果(FVD)