A GOOD IMAGE GENERATOR IS WHAT YOU NEED FOR HIGH-RESOLUTION VIDEO SYNTHESIS
摘要
类似于 styleVideoGAN,本文也提出了一种使用预训练的 GAN 逆映射进行视频生成,区别于 styleVideoGAN,本文:1. 一种对动作隐式建模的网络结构,2. 在视频域和图像域进行判别器训练,3. 加入了对比学习的损失。总体来说,本文堆叠了很多 loss,在多个方面对网络进行了限制,取得了不错的结果。
概览

创新
- 使用基于 LSTM 的结构组建了一个运动生成器,用以隐式地建模运动(表示为隐编码残差)
- 显式约束运动生成器对运动进行多样性建模的损失函数
- 对图像和视频分别使用判别器
- 使用对比学习额外训练视频生成器
网络
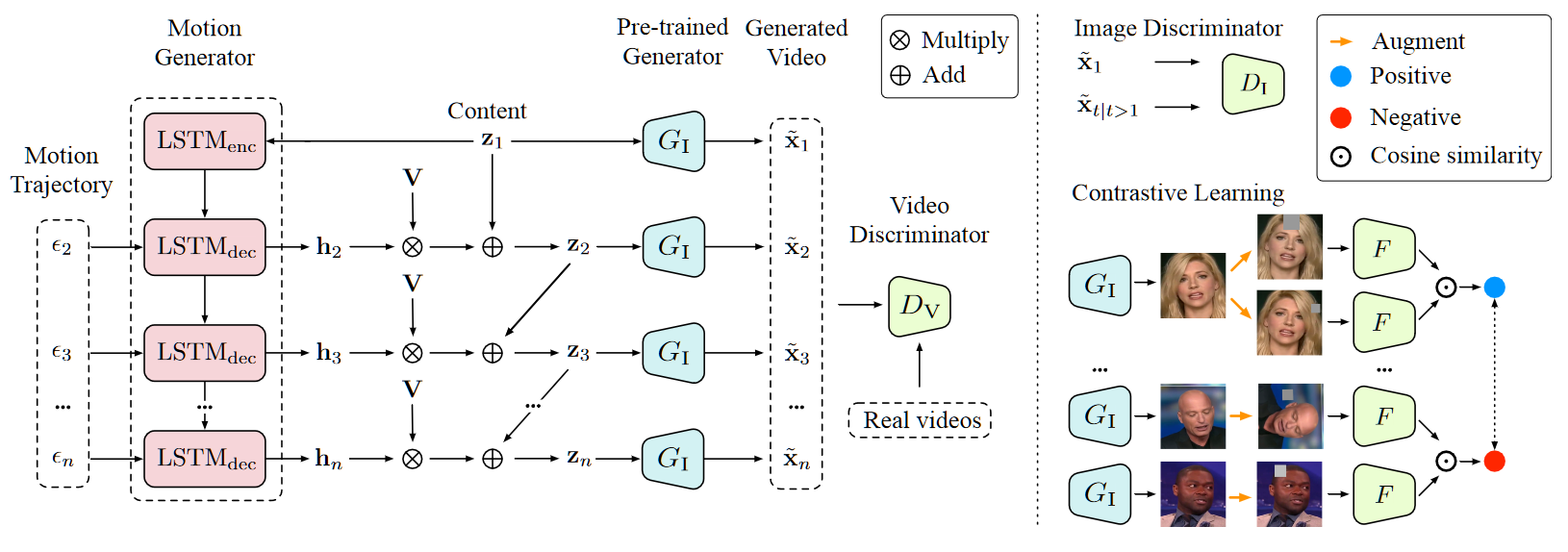
上图中左半部分描述了主要的 backbone,输入包括隐编码 $z_1$(从 mapping 之后的空间采样),运动轨迹噪声 $\epsilon_t$(从正态分布采样),PCA 基向量 $V$,输出为第二帧以及后续帧的隐编码 $z_t$,并通过图像生成器 $G_I$ 生成对应的视频帧 $\{\tilde x_t\}$,将其输入判别器 $D_V$ 进行对抗学习。
右上部分表示对判别器对抗部分,除了用 $D_V$ 直接判别整个视频 $\{\tilde x_t\}$ 之外,还需要将每一个 $\tilde x_t$ 单独输入图像判别器 $D_I$,右下部分表示对 $G_I$ 的监督除了对抗性监督之外还有一个对比监督,代理任务为个体判别。其中 $F$ 为和 $\rm LSTM_{enc}$ 结构基本一致的编码器。
具体来说,其前向过程如下:
初始化
从预训练的 $\mathcal W+$ 空间(或其他分布)中采样第一帧隐编码 $z_1$
从正态分布中采样 $t-1$ 个 $\epsilon_t$,用以生成多样性的运动
- 对 $\mathcal W+$ 空间进行多次采样,计算多次采样的 PCA 基向量 $V$
运动生成器
- 首先将 $z_1$ 输入 $\rm LSTM_{enc}$,用以初始化整个 LSTM,得到 $(h_1,c_1)$,其中 $h$ 表示隐状态,$c$ 表示单元格状态
- 递归生成所有的隐状态和单元格状态:$h_t,c_t=\mathrm{LSTM_{dec}}(\epsilon_t,(h_{t-1},c_{t-1}))$
- 对于每一个帧的隐状态,使用残差的方式建模运动(这种方式在理论上可以将运动和外观进行解耦),具体来说每一帧的隐编码 $z_t=z_{t-1}+\lambda\cdot h_t\cdot V$,其中 $\lambda$ 为超参数
- 实验过程中发现很多时候运动生成器完全忽略了 $\epsilon_t$ 的作用,因此计算互信息(相似度) loss:$L_m=\frac1{n-1}\sum^n_{t=2}sim(H(h_t),\epsilon_t)$,其中 $sim(u,v)=\frac{u^Tv}{||u||\cdot||v||}$,$H$ 是一个两层 MLP
视频生成器
- 图中显示得很清晰,$G_I$ 通过作用于每一帧 $z_t$ 从而生成最终的视频 $v$
- 其中,$G_I$ 的生产能力来自于三方面的监督:
- 视频对抗 loss:$L_{D_V}$
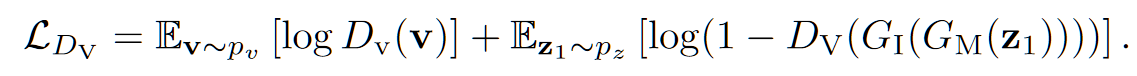
- 图像对抗 loss:$L_{D_I}$
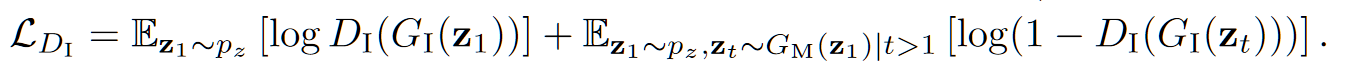
- 对比学习 loss:$L_{contr}$
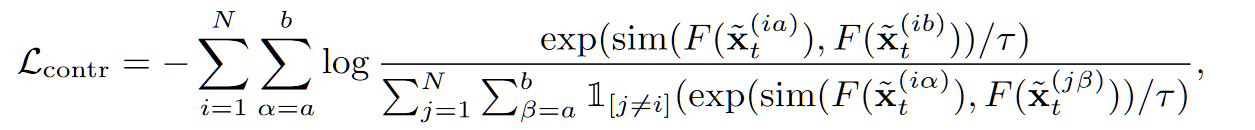
- 视频对抗 loss:$L_{D_V}$
- 其中对抗损失都是普通的 GANLoss,对比学习损失意味着:将某帧生成的图像进行不同的数据增强得到正样本 / 将某两个视频的生成图像进行相同(或不同)的数据增强为负样本
总体的 loss 在上述四个 loss 之外,参考 pixel2pixelHD 设计了生成的第一帧和其他帧之间的特征匹配损失 $L_f$,用以显示视频的语义一致性
整体的优化 loss 为:
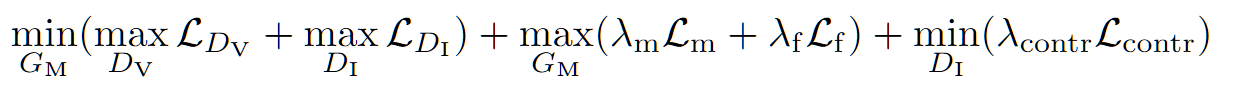
结果
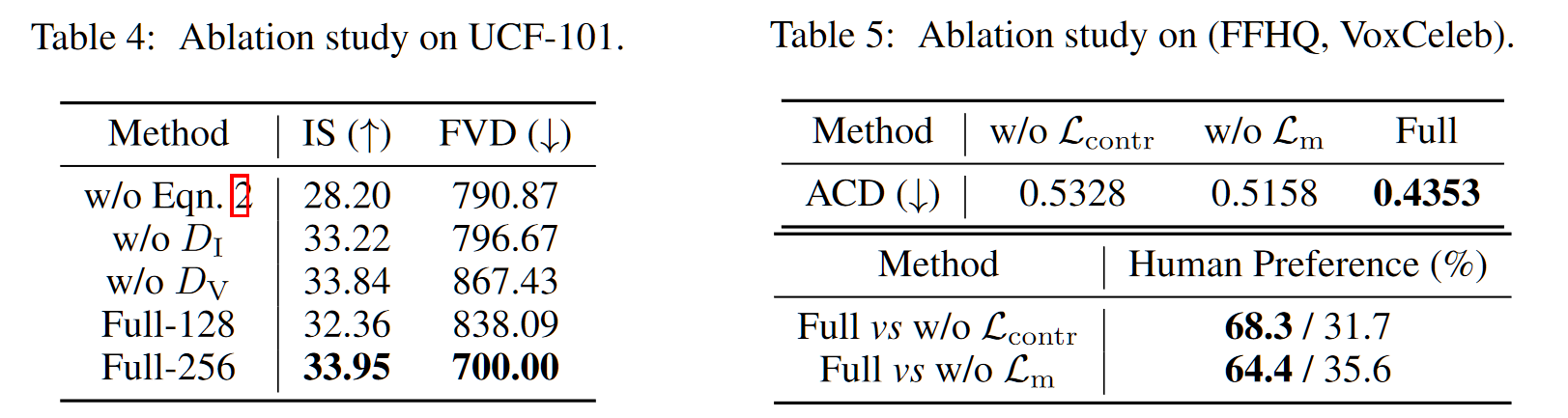
- 视频生成指标,其中 ACD(Average Content Distance) 指标继承自 MoCoGAN,用以度量一个视频中的人脸是否 ID 保持一致
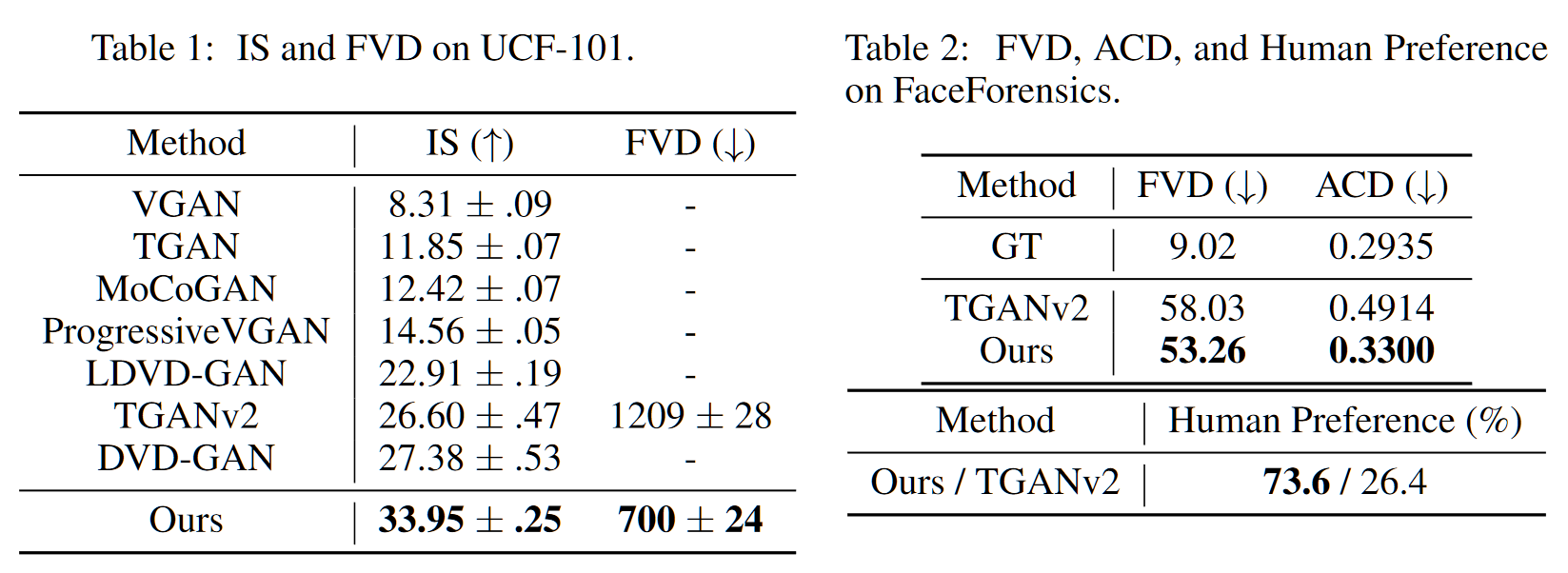
- 视频预测指标

- 更进一步,本文实现了跨域的视频生成,可以看出在人脸上训练的网络对于类人脸的动物或者动漫都有一定的迁移能力,同时能看出具备一定的多样性

- 在不同数据集上的消融实验