MAGVIT: Masked Generative Video Transformer
摘要
本文提出了一种基于 3DCNN 的 VQGAN 和多任务优化的视频生成器。其中 3DCNN 的网络由图像预训练的 2D 网络中心膨胀而来。所谓多任务优化,即通过不同的 mask 模拟不同的条件任务(包括帧插值、帧预测等十种),另外加上自重建任务进行联合优化。其中条件任务又分为:1.预测完全不存在的帧,2.预测部分存在的帧。因此第二部分可以描述为使用多任务构造损失函数联合优化 VQGAN 的下标重建 transformer。
概览

创新
- 先训练 2D-VQGAN 再膨胀为 3D-VQGAN 的策略
- 对视频进行多任务 mask 联合优化的策略
tricks
- 使用中心膨胀获得 3D 预训练权重
- 对视频的每一帧计算感知损失
- 在 GAN 的损失函数上加入 LeCam 正则化
网络
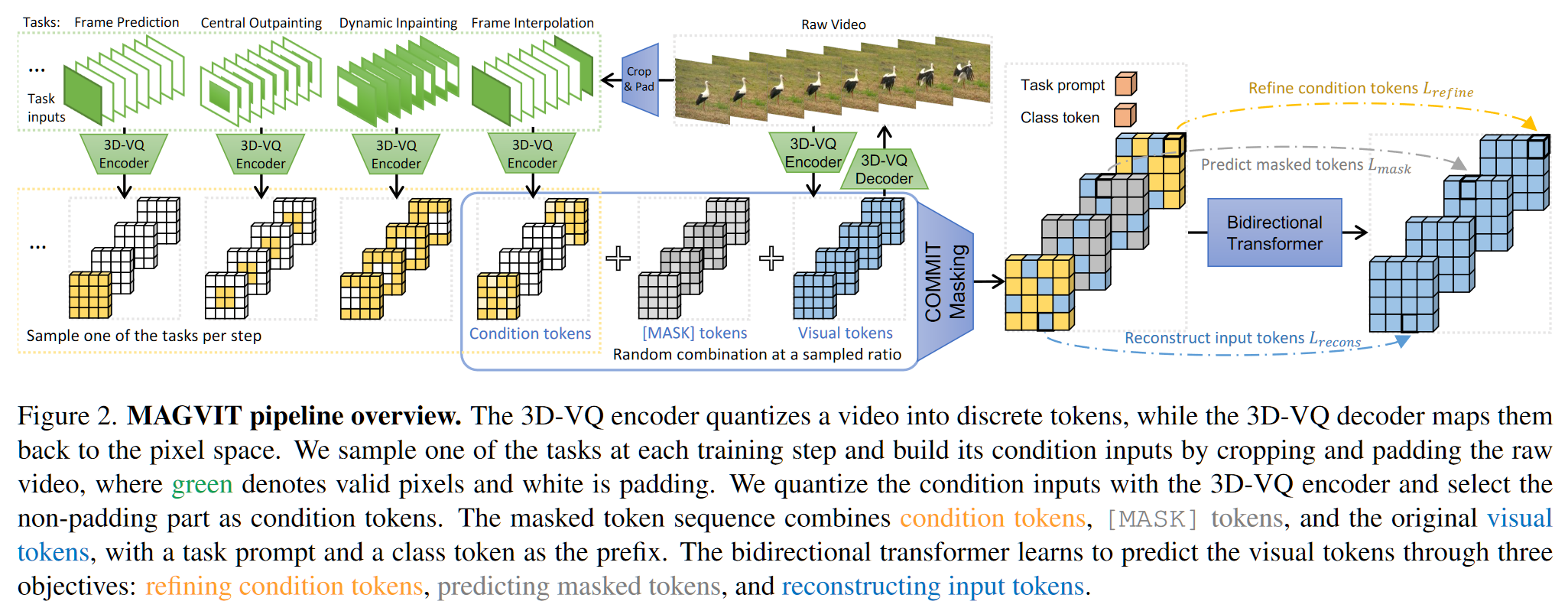
上图中,3D-VQ Encoder 将视频量化为离散的标记,而 3D-VQ Decoder 将它们映射回像素空间。在每个训练步骤中对任务 $\rho$ 进行采样(共十种任务),并通过裁剪和填充原始视频来构建其条件输入 $c$,其中绿色表示 GT 像素,白色表示填充,橙色表示 GT tokens。使用用 3D-VQ Encoder 量化条件输入,并选择非填充部分(橙色)作为条件标记。掩码 token 序列(即图中 COMMIT Masking)结合了条件 tokens、[MASK] tokens 和 GT tokens,并以任务提示符和类令牌作为前缀($[\rho,c]$,直接 Concat)。transformer 通过三个目标学习预测可视标记:细化条件标记、预测屏蔽标记和重构输入标记。
本文提出的 MAGVIT 是一个两阶段的模型,首先训练一个 3DCNN 的 VQGAN,第二阶段再通过多任务 mask 学习一个 transformer 预测 token。
第一阶段将编码器和解码器分别描述为 $f_\tau:V\to z,\ f_{\tau^{-1}}:z\to V$。第一阶段训练的 VQGAN 由 2DCNN 的预训练模型膨胀得到,在图像上训练的 2D-VQVAE 遵循如下优化模式:
- $I$ 表示图像,$z$ 表示图像经过编码器 VQ 之后的下标序列,长度为 N
- $m$ 为 mask,是一个二元向量,对于 $m$ 的每一个值为 $x\to x/[mask]$,经过 mask 的 $m(z)$ 记作 $\bar z$
- 训练时,$m$ 从先验分布 $p_\mu$ 之中采样,即其中 $x\to[mask]$ 占比遵循余弦调度函数 $\gamma(\cdot)$
- 采样的具体操作为:
- 从 $U(0,1)$ 中均值采样 mask 分数 $s$ 和一个中间变量 $r$,使用 $r$ 计算 $\lceil \gamma(r)N\rceil$,这个值表明小于阈值 $s^$ 的 $s_i\in s$ 的个数,以此确定阈值 $s^$
- 得到 $m_i(x)=[mask]\ \ \ \ if\ \ \ \ s_i\leq s^*\ \ \ \ else\ \ \ \ x$
- 优化目标为:$L_{mask}(z; θ) = E_{m∼p_\mu} [∑_{\bar z_i =[MASK]} − \log p_θ(z_i | [c, \bar z]) ]$
3D-VQVAE 采用中心膨胀的方式获得预训练的权重,这样可以在 GAN 的训练中快速达到稳定状态。同时在视频训练时将 VGGLoss 应用于每一帧的图像上,在 GANLoss 中加入了 LeCam 正则化(CVPR2021) 用以稳定对抗训练。
第二阶段的训练采用多任务 mask 的方法进行建模,原文称之为:内部令牌的条件屏蔽建模(COnditional Masked Modeling by Interior Tokens )简记为 COMMIT 方法。在训练时从十种不同的条件生成任务中进行采样,具体来说任务包括:帧预测(FP)、帧插值(FI)、中央外绘(OPC)、垂直外绘(OPV)、水平外绘(OPH)、动态外绘(OPD)、中央补绘(IPC)和动态补绘(IPD)、类条件生成(CG)、类条件帧预测(CFP)。其中每个任务的具体定义见原文 P12 附录 B.1。
在第二阶段的训练过程中,其整体逻辑与第一阶段训练图像 2D-VQ 一致,但在细节上略有改动:
- 首先采样原视频 $V$,采样一个任务提示符 $\rho$,并根据 $\rho$ 生成对应的 mask 任务视频 $\tilde V$
- 记 $z=f_\tau(V),\ \tilde z = f_\tau (\tilde V)$,得到对应 tokens 的 mask 结果 $m_i$:
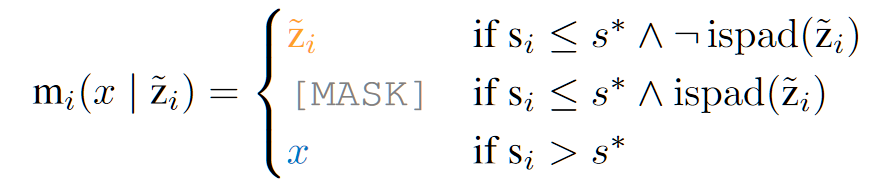
- 其中 ispad(·) 表示是否为全填充,对应至上图 backbone 之中,表示为全白色的 token
- 一阶段图像的loss描述为:$L_{mask}(z; θ) = E_{m∼p_\mu} [∑_{\bar z_i =[MASK]} − \log p_θ(z_i | [c, \bar z]) ]$,因此据此写出视频的描述应为:$L(V; θ) = E_{\rho,\tilde V}[ E_{m∼p_M} [∑_i − \log p_θ(z_i | [\rho,c, \bar z]) ]]$
- 其中用 $p_M$ 而非 $p_\mu$ 是因为在当前的 $m_i$ 获取方式下,其分布已经和图像层面不一致了,故用一个新的符号
- 此式按照 $m_i$ 的三种不同取值可以拆分为三个部分:
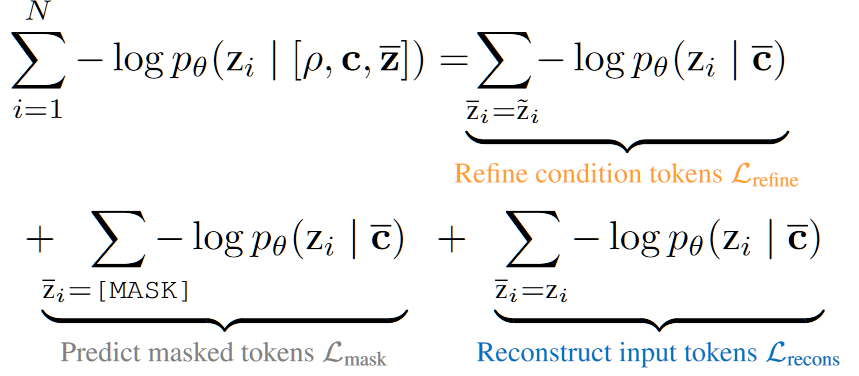
- 这三部分分别表示了:1.条件生成(10种具体任务的某些帧)2.完全预测(10种具体任务的某些帧)3.视频重建(单独的任务+10种具体任务的某些帧)
推理

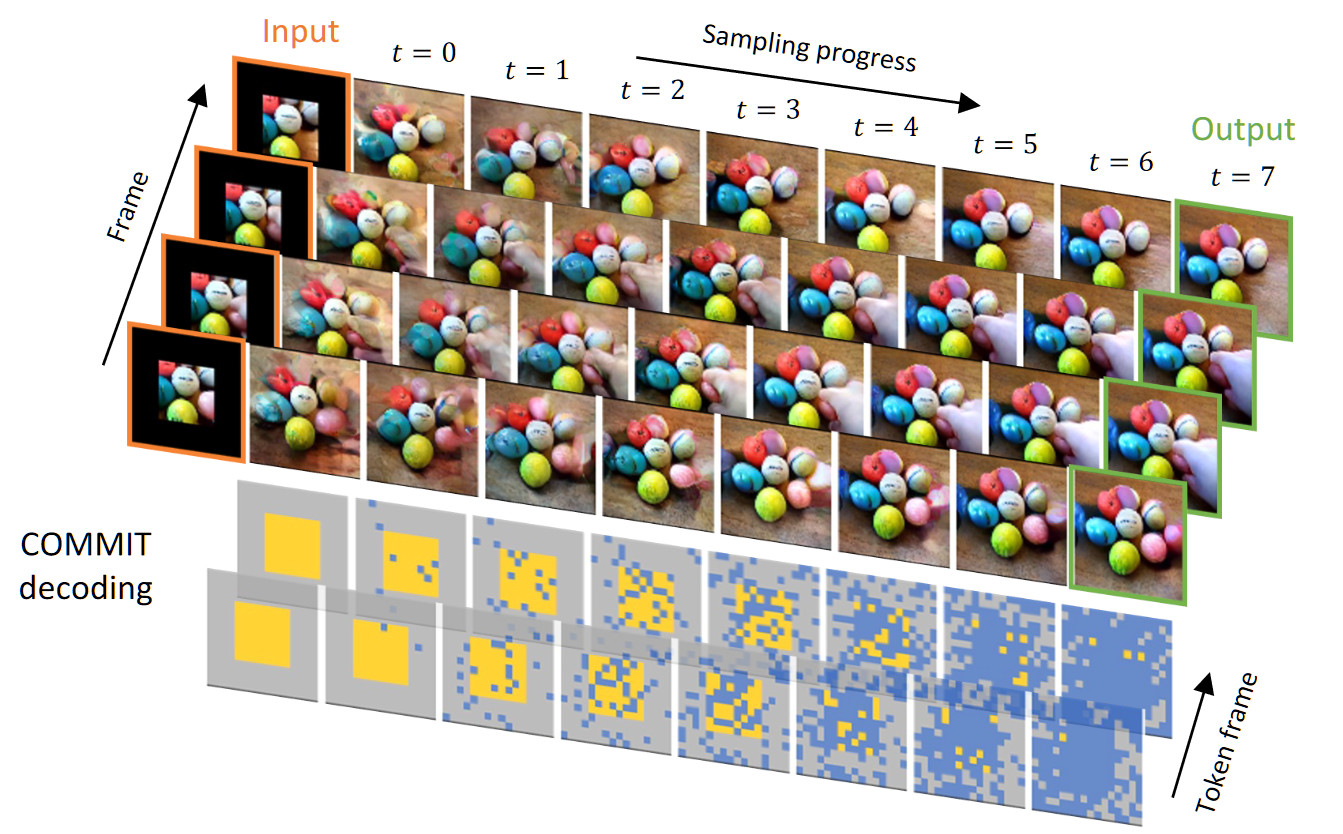
推理的过程中采用上图的推理方式,具体来说是:COMMIT 解码从 $m_i$ 入手,在 $m_i$ 和对应的 $s_i$ 的指导下,通过在每一步替换一部分新生成的 token 来执行向输出 token 的条件转换过程(具体的替换个数由更新 $s^*$ 的值确定,而这个值由 $t$ 确定,$t$ 表示第几步,总共 $K$ 步,$K$ 手动选择),并最终预测所有 token。
下图展示另一个边界预测任务下的 7 步推理可视化过程:
结果
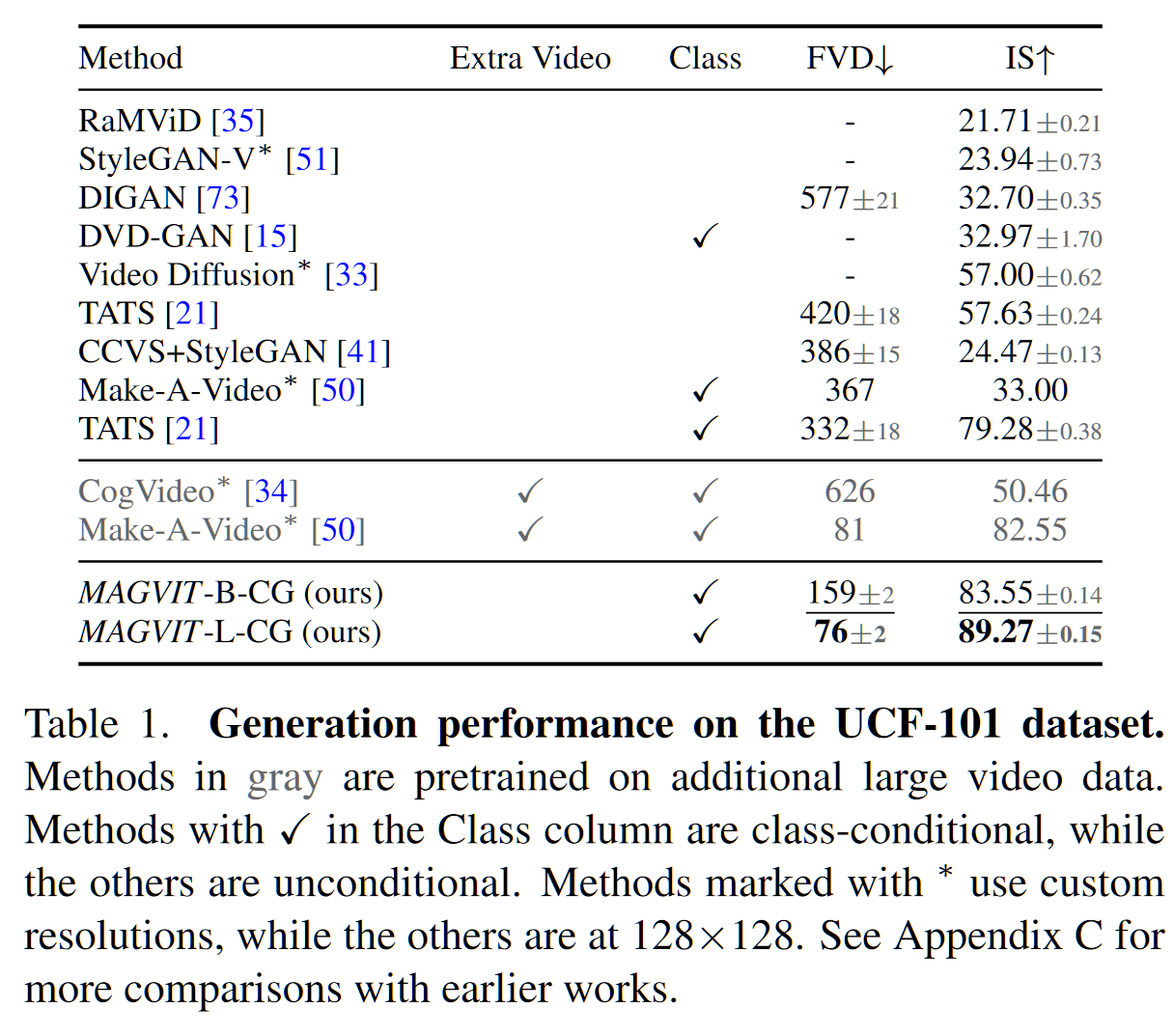
- 在视频生成上针对 UCF-101 的 FVD
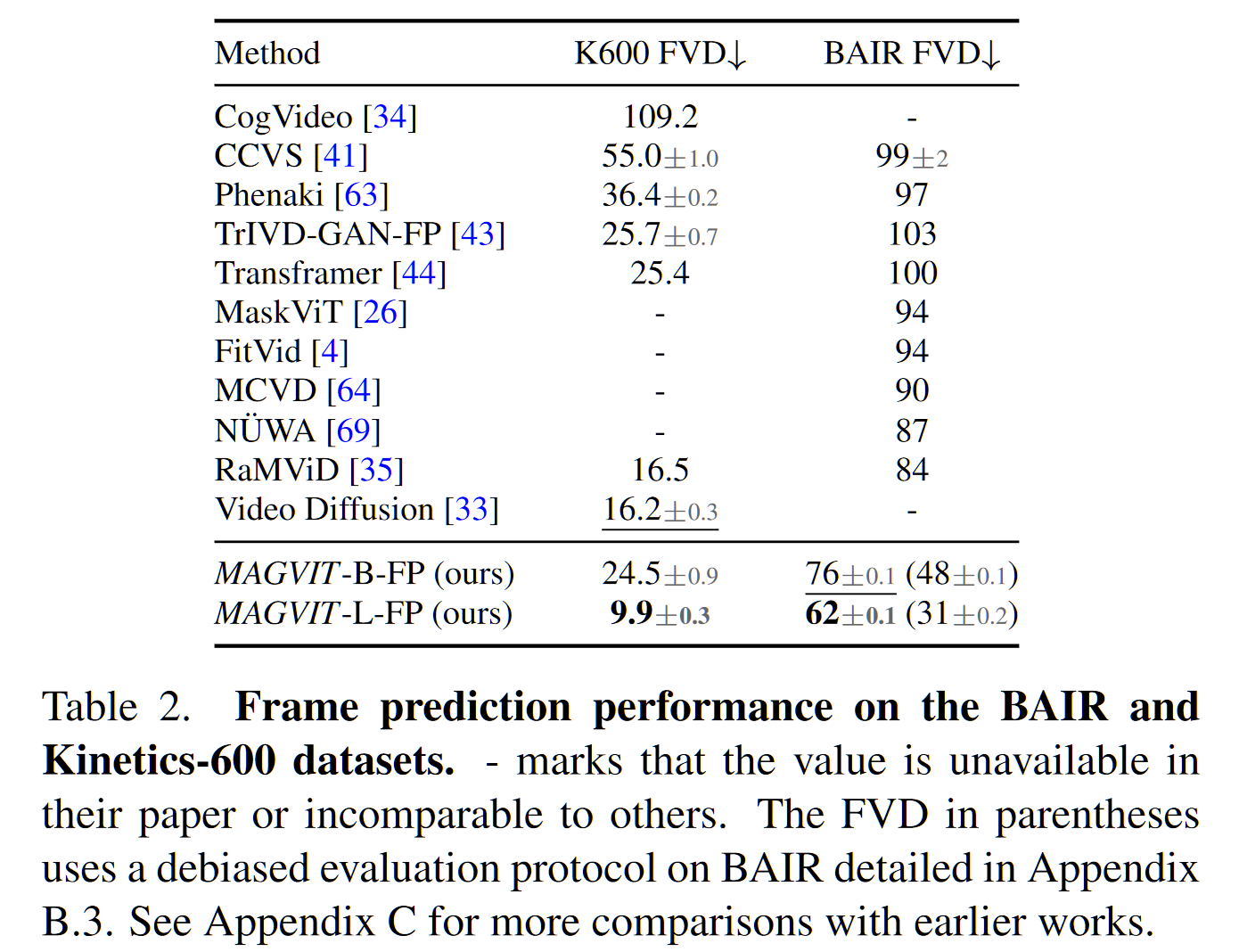
- 在帧预测任务上针对 K600 和 BAIR 的 FVD
更多的结果可视化见网站:https://magvit.cs.cmu.edu