Disentangled Image Colorization via Global Anchors
摘要
对于图像上色问题,其具备两个特性:1. 任意像素点的色彩值具备不确定性,2.逻辑上属于同一个物体的像素点在上色之后应当具有一致性。归结来看,第一个特性即为色彩分布,需要预测一个具体切合理的色彩分布概率,这个问题可以转化为颜色分类问题,第二个特性即为空间一致性,需要一个可以用于区分不同位置色彩是否一致的数据,这个问题可以转化为聚类问题。本文从上述两个特性入手,一方面使用SPixNet等方法对图像进行分割,并将分割的子“超像素”进行聚类从而解决空间一致性,另一方面在同类的“超像素”上应用分类器预测出的色彩值。
概览

创新
- 解离了颜色一致性和不确定性的特征
- 使用像素分割+聚类的方式解决色彩一致性问题
网络
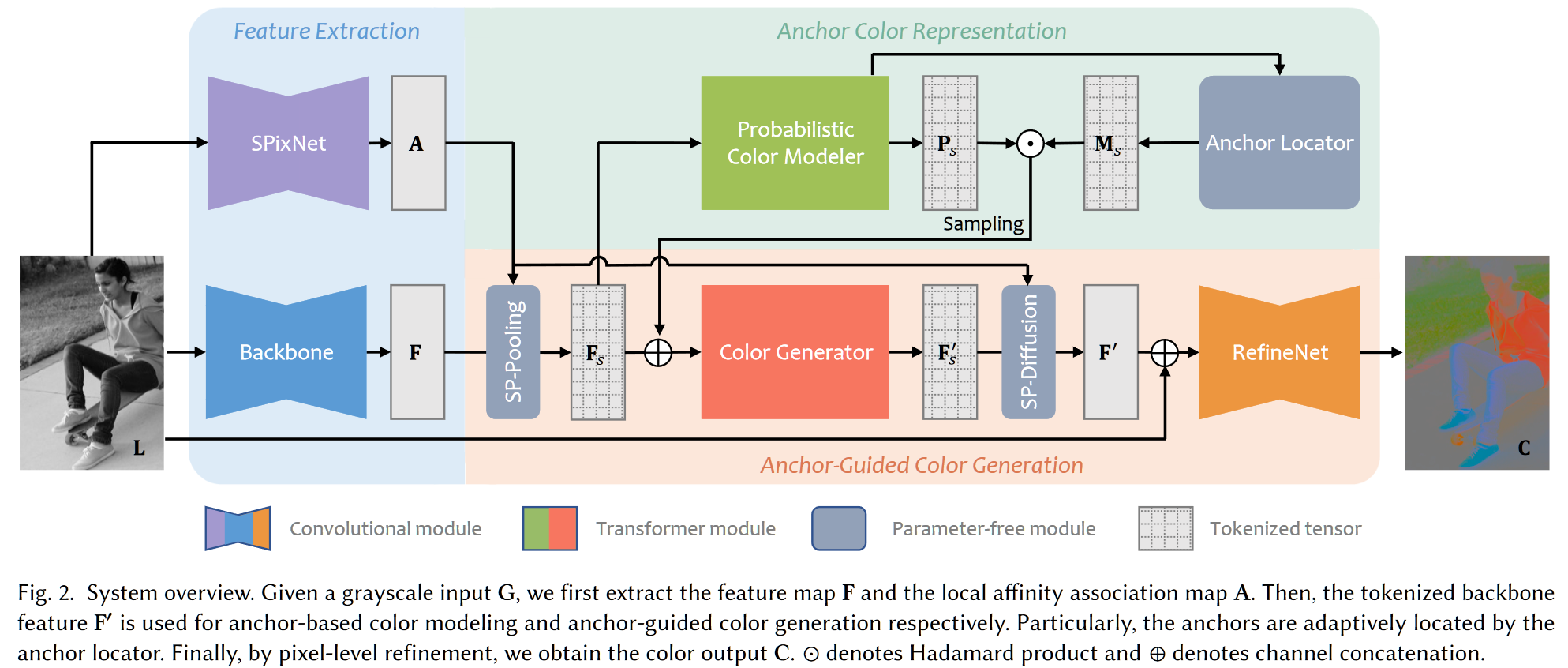
总结性质地讲,上图中各个符号/网络都有其含义
- $L$,输入的灰度图 $(N,C,H,W)$
- SPixNet,用于从 $L$ 中提取基于像素属于周边超像素的概率信息 $A (N,9,H,W)$,表示每个像素位于哪个相邻的超像素
- Backbone,用于从 $L$ 中提取基于像素的特征信息 $F (N,64,H,W)$,表示基于像素的特征图
- SP-Pooling,用于使用像素到超像素的关联图 $A$ 池化基于像素的特征信息 $F$,获得基于超像素的特征信息 $F_s (N,64,H’,W’)$
- 同时获取的还有基于超像素的色彩信息 $C_s (N,2,H’,W’)$,基于超像素的位置信息 $L_s (N,64,H’,W’)$
- 这里的 $H’, W’ = H/16, W/16$,具体和池化尺寸有关
- Probabilitic Color Modeler,用于从基于超像素的信息 $F_s,C_s,L_s$ 中估计超像素的颜色预测值 $P_s (N,313,H’,W’)$,313 指色彩分类,该值回传用以计算超像素色彩和 GT 的 loss
- Anchor Locator,用于从基于超像素的信息 $F_s,C_s,L_s$ 中估计超像素的聚类信息,生成掩码 $M_s (N,1,H’,W’)$,第二维表示属于哪一个聚类
- Color Generator,使用基于超像素的色彩概率预测以及基于超像素的聚类信息,生成空间一致,色彩确定的最终超像素色彩特征 $F_s’$ $(N,64,H’,W’)$,该特征直接通过 MLP 映射至 $(N,2,H’,W’)$ 作为超像素的色彩回传,用以计算 loss
- SP-Diffusion,使用基于像素属于周边超像素的概率信息 A 引导关于超像素的特征 $F_s’$ 进行向像素的扩散,生成含有上述所有信息的、基于像素的特征 $F’ (N,2,H,W)$,该结果可以作为最终输出
- RefineNet,对 $F’$ 进行进一步的色彩增强,增强的监督方式为使 VGGLoss 更小,从图像上看可以解决无聚类中心导致的无色彩 / 多聚类中心导致的色彩不一致问题
前向
首先介绍超像素,其为比一般像素更大的“软像素”,通常初始化时将各个超像素均匀地分配为方格,接着对于某个像素位置,其可能位于其本身所在的超像素或者周围八个超像素之中,因此对于一个像素 $p$,其有可能位于 9 个超像素 $s$ 中。通过不停地迭代细致化超像素的边界,即可得到超像素分割图。

- 在训练阶段,输入包括灰度图 $L$ 和色彩图 $C$,首先经过 SPixNet 和 backbone 分别得到 $A,\ F$,这两个特征分别表示超像素图和像素特征图
- 所谓的 backbone 其实就是基于 CNN 的特征提取器, $A\to(N,9,H,W)$,$F\to(N,64,H,W)$
- 使用 $A$ 引导 $F$ 和 $C$ 进行池化得到含有超像素信息的特征 $F_s$,具体来说,使用属于不同相对位置的超像素的概率对特征进行加权,等价于多次 $Avgpool(Concat(F,C) \times A[i])$
- $F_s$ 对应 $(F,C)$,包含两个部分,超像素特征,超像素色彩,这两部分特征均是基于超像素的。
- 超像素的数目由分割方式决定,本文采用均匀分割成多个大小为 $S\times S$ 的超像素,$S=16$,因此 $F_s\to(N,64+2,\frac H S,\frac W S)$
- 同时在这一步还会产生一个对超像素特征进行位置编码的位置向量 $F_p\to(N,64,H’,W’)$
- 最终记录的也就是超像素的特征向量和位置向量,其数学表示如下
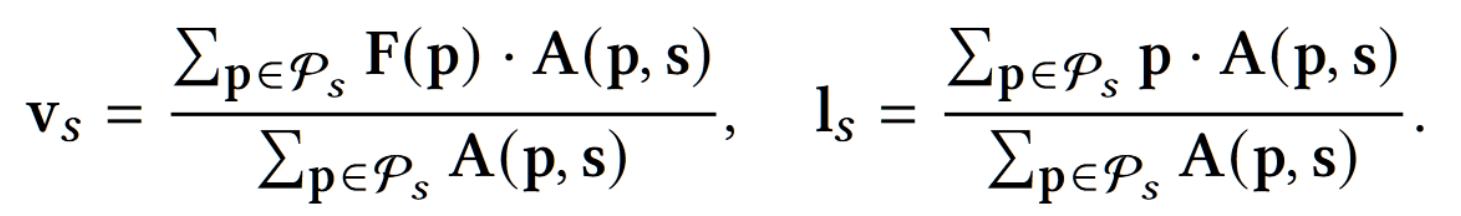
- 使用基于超像素的特征用来进行基于超像素的颜色概率预测(Probabilitic Color Modeler),具体来说
- 拉平超像素特征和超像素位置获得 $F_{fs},\ F_{fp}\to(H’W’,N,64)$
- 基于 $A$ 获得了一个针对每个超像素的 mask,拉平后得到 $M_{fs}\to(N,H’W’)$
- 输入一个 6 层的 transformer,$q=k=F_{fs}+F_{fp},\ v=F_{fs},\ mask=M_{fs}$
- 上一步得到的输出再经过一个投射层即为图中 $P_s\to(N,313,H’,W’)$,其表示了每个超像素的色彩的分类概率
- 使用超像素色彩进行聚类(Anchor Locator),这是一个无参的过程。聚类的结果是一个 mask $(N,1,H’,W’)$,其表示了某个超像素属于哪一个类别,拉平之后为 $M_s\to(H’W’,N,1)$
- 使用基于超像素的色彩分类预测和基于超像素的特征进行超像素色彩生成(Color Generator),具体来说
- 将超像素的色彩进行色彩映射(2维ab色彩空间映射至313维分类色彩)之后进行 one hot 编码,得到一个 313 维的向量,该向量本质上是由 $C_{fs}$ 生成的,因此仍由 $C_{fs}$ 代替
- 输入一个 6 层的 transformer,$q,k,v$ 均来自于 $Embedding(F_{fs}+M_s\odot F_{fp})$ 的变形
- 输出的值记为 $F_s’\to(N,313,H’,W’)$,其表示了超像素最终的色彩预测分类
- 使用 $A$ 引导 $F_s’$ 进行扩散(逆池化)可以还原出基于像素的特征和位置信息,即使用超像素的特征向量和位置向量($v_s$ 和 $l_s$)可以还原像素的对应特征 $F’\to(N,313,H,W)$:
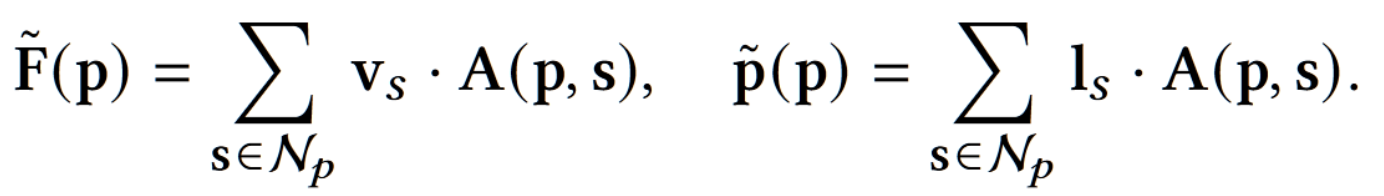
- 最终使用 RefineNet(是一个由 CNN 构成的网络)进行微调,并将 313 的色彩分类转化为 ab 空间的色彩特征,即可以输出色彩图 $C_{pred}$
训练
本文采用两阶段的训练,首先训练SPixNet,这个网络来自已有的工作SPixelCNN。其中与原文不同的是,原文使用 $(c)$ 预测 $(b)$ 然后使用新的 $(c)$ 作为输入,而本文则使用 $(c)$ 预测 $(b)$ 之后使用新的 $(a)$ 作为输入,其原理是图像的灰度图和RGB图具备基本一致的亮度信息,因此使用色彩图训练得到的超像素分割网络也可以分割灰度图。第一阶段的损失函数遵循 SPixelCNN 的设置,目标是:1. 使超像素还原出的像素的色彩信息和像素的 GT 色彩信息尽可能一致,2. 使每个超像素包含的像素位置信息尽可能紧凑
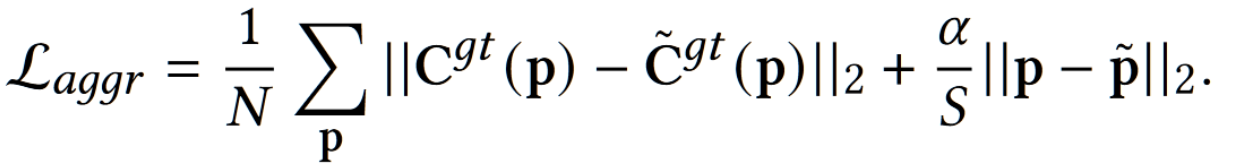
第一阶段训练完成之后接着训练第二阶段,第二阶段的目标是优化剩余的所有含参网络,其目标主要包含三个:
- 对每一个超像素,将 $P_s$ 和基于真实像素做池化后的 313 色彩分类类别计算交叉熵损失,此时由于超像素分割网络可以很好地进行池化和扩散,因此这里可以同步优化 backbone,Probabilitic Color Modeler
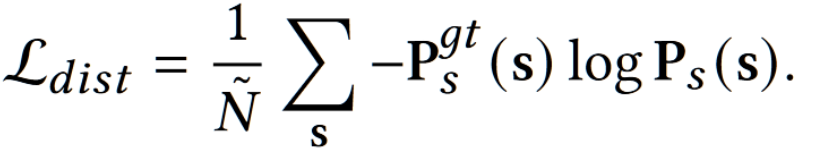
- 对每一个超像素,将 $F_s’$ 和基于真实像素做池化后的 313 色彩分类类别计算交叉熵损失,可以优化 backbone,Probabilitic Color Modeler,Color Generator
- 计算生成的 ab 空间图像和 GT 图像计算感知损失,可以优化 backbone,Probabilitic Color Modeler,Color Generator,RefineNet
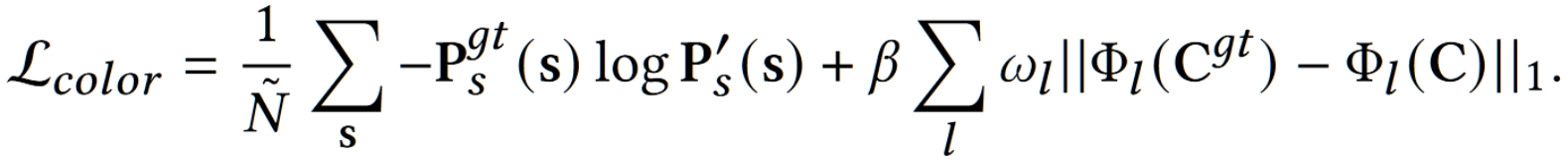
第二阶段最终的损失函数写为:
结果
效果图如下:

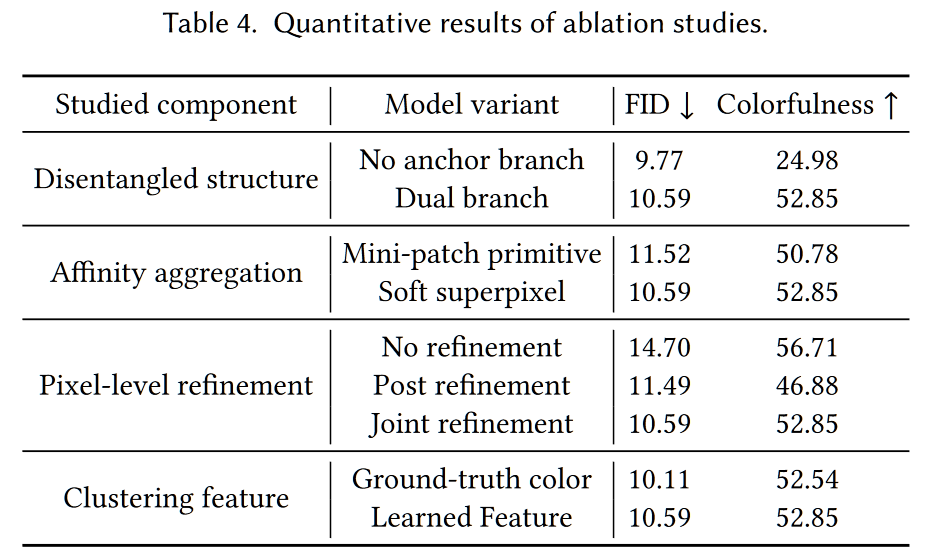
量化指标上,由于彩色化的目的是生成视觉上看似合理的颜色,而不是恢复 GT,那些基于 GT 的保真度度量(如PSRN、SSIM、LPIPS)不适用于评估,相反,与视觉感知相关的度量(如FID、IS 和 Colorfulness)更能反映所需的彩色化质量。
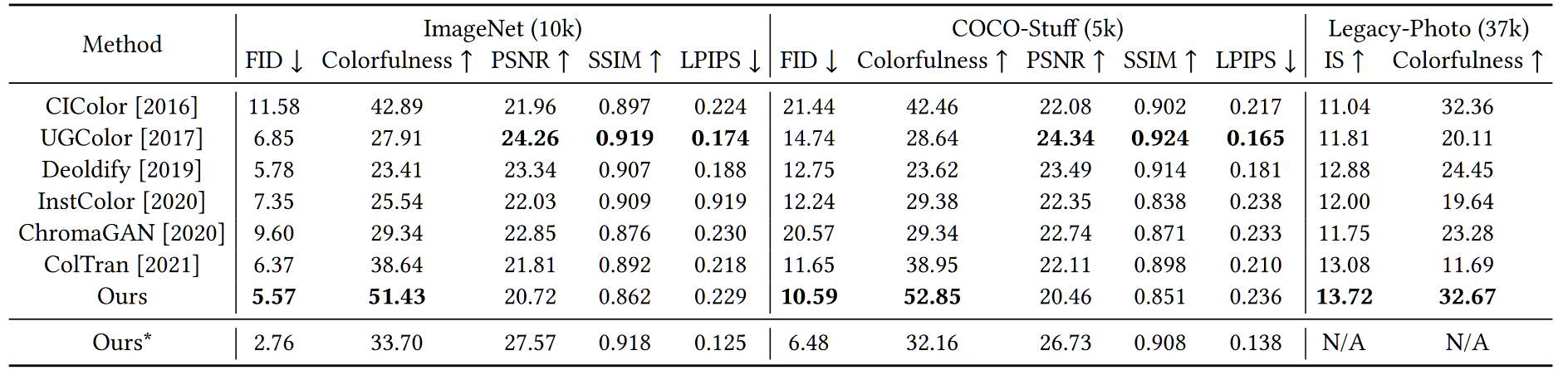
消融实验上主要做了锚点的个数对超像素聚类的影响探索

同时在是否存在锚点分支、是否进行软像素分割、是否进行基于像素级别的增强、是否进行特征聚类四个方面分别进行了消融实验。