📌home目录下只放代码源程序;训练日志、模型权重文件、数据集放在data目录下
每个服务器可能有data,data1,data2目录,使用df -h查询空间占用📌自行安装使用miniconda管理自己的python环境
📌
pip install gpustat,使用gpustat查看无人使用的卡进行使用
尽量避免在别人使用中,但是没有占满显存的卡上跑实验,会严重影响速度
如果使用jupyter服务器运行程序,在程序结束后记得手动释放内存自己下载的新数据集 / 使用新方法处理的数据集 可以联系楚舒扬更新此页面。
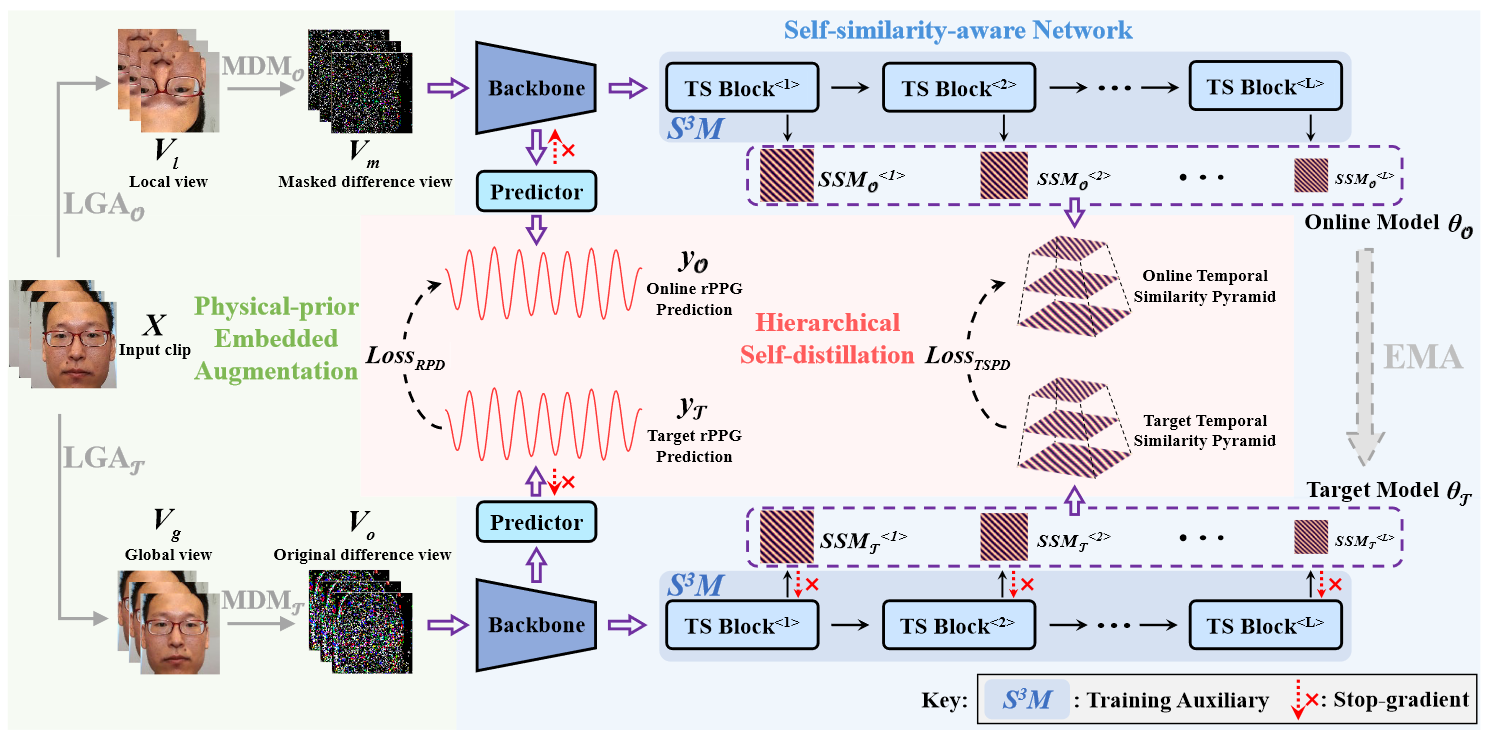
CFAT
TLC
SSPD
Self-similarity Prior Distillation for Unsupervised Remote Physiological Measurement
abstract
本文提出了一种新的 rPPG 自监督结构,相对于对比学习强调的正负样本,本文更关注 rPPG 信号的自相似性,这种自相似性可以看做周期性,所谓的“分层蒸馏”也是正样本对的一种形式。尽管对比学习本身没有明确的缺点,但有些文章喜欢通过和对比学习划清界限显得自己很 novel。事实上本文也用到了正样本对,并且由于没有负样本的有效性监督,需要指出本文提出的 SSPD 结构在逻辑上无法避免模型的模式崩溃。
overview
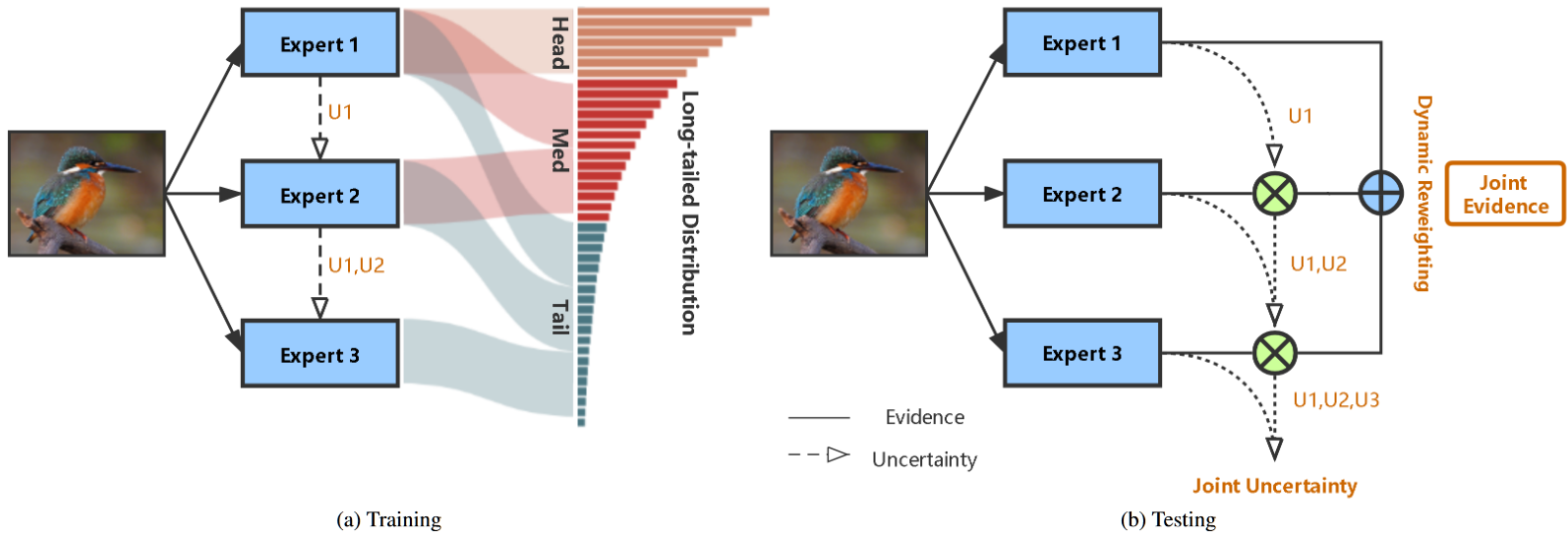
BoxSnake
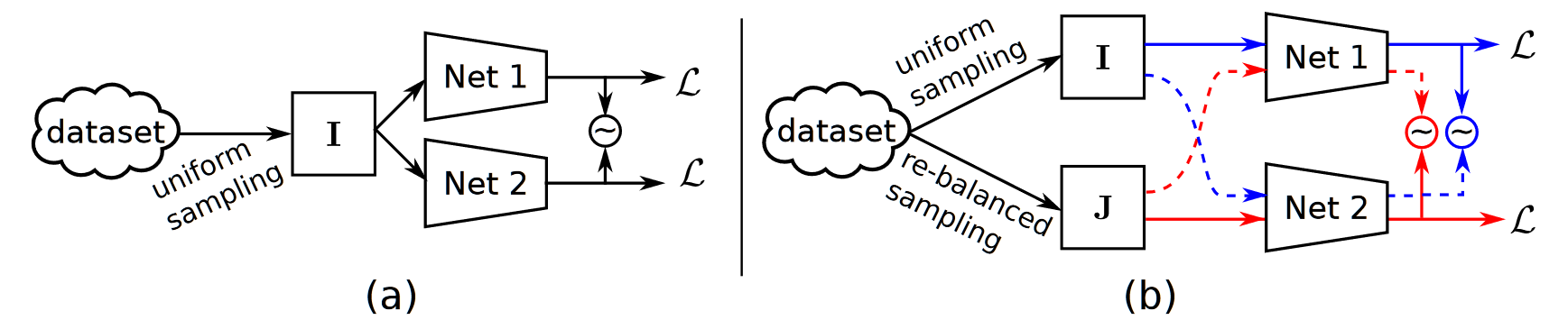
multi-network learning rPPG
Contactless Pulse Estimation Leveraging Pseudo Labels and Self-Supervision
【rPPG】【ICCV2023】【paper】【code not available】
abstract
本文提出了一种使用伪标签监督辅助对比学习的无监督范式,使用 2SR 生成伪标签并通过课程式学习逐步平衡伪标签监督和对比学习。关于伪标签监督是多网络学习在 rPPG 的一种成功迁移。需要指出本文将视频 $x$ 转化为了 STMap,但在之后多次用到 $\phi(x)$,难免造成模型直接处理视频的误会。
overview
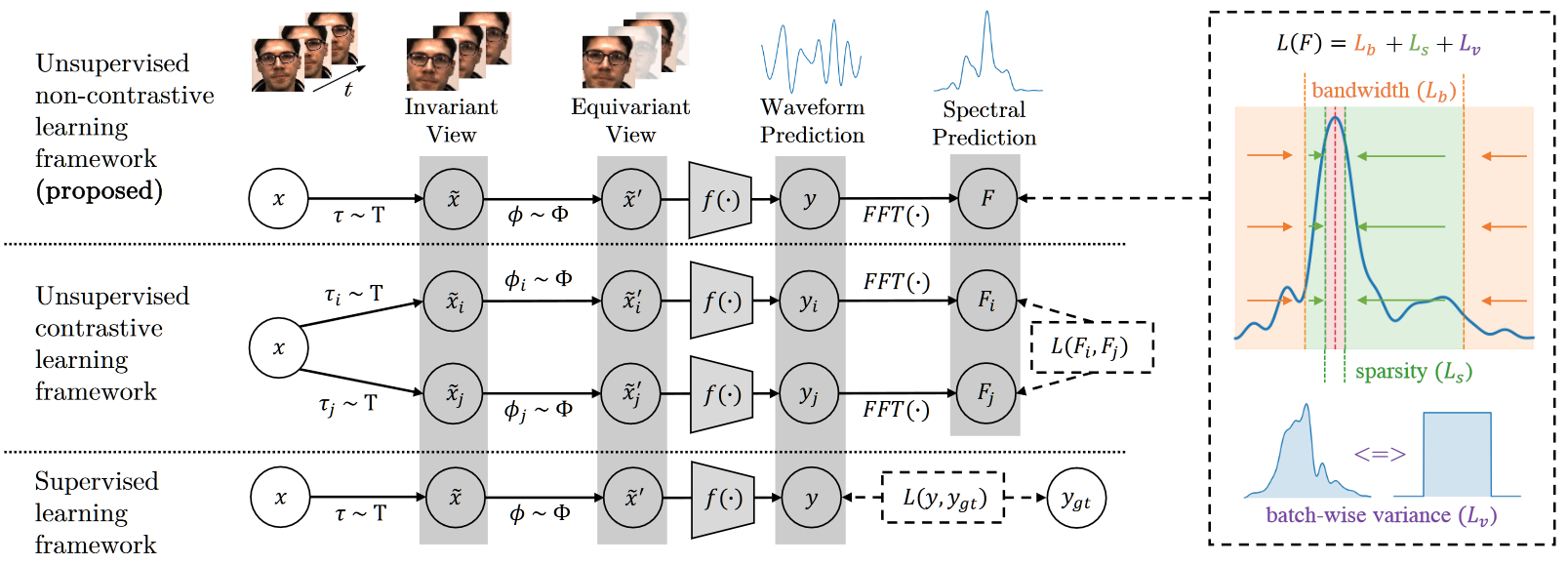
SiNC
Non-Contrastive Unsupervised Learning of Physiological Signals from Video
abstract
本文基于 PPG 信号的三个特征,提出了一种非对比学习的自监督方法用于 rPPG 测量,虽然作者强调了没有针对 rPPG 进行独特的网络设计,但是三种特征均为 PPG 信号强相关的,并且这项工作实际上可以看做“基于负样本和先验约束的对比学习”。需要指出:作者认为在同 batch 内的 PSD 之和应当分布均匀,这是显然不成立的,即使考虑 batch size 可以很大并且视频经过数据增强,在统计学意义上 PSD 之和仍应该服从正态分布。
overview